THIS CHAPTER WILL DISCUSS:
1. The ways in which the research that compares groups with individuals has evolved since the 1920s.
2. The types of group tasks.
3. The various ways to evaluate the tasks.
4. Why groups perform some tasks better while individuals are more effective at performing others.
5. How group size affects process and output variables.
6. What factors group organizers should consider when choosing an ideal size for a group.
INTRODUCTION
"Are groups or individuals better at performing tasks?" This question is clearly a very important one. Suppose it were true that groups do not perform tasks as well as individuals. There would be little motivation to form groups at all, and there would be little reason for scientists to study group process or for us to write this book.
However, people do work together in groups. In fact, people work in groups so often that we might be tempted to conclude that groups definitely perform tasks better than individuals. We should not reach this conclusion too hastily, however. In actuality, the performances of groups and individuals depend on many factors. We will be discussing these factors shortly. Before we do, though, we have to look more closely at the question "Are groups or individuals better at performing tasks?" We need to decide if this is the proper research question for our topic.
Does the question really give us a complete idea of the answers we seek? Will it perform the function of helping us to understand how groups and individuals work? Not really. The wording of the question is too vague to help us as it should. Fortunately, the scientists who investigate small groups have fine-tuned this important question in order to make it less vague. Using their work, we shall discuss how we can make the question specific enough to help us. Our ideal is to understand when it is a good idea to have a group perform a task and when it is better to let individuals do the job.
What Is "Better"?
First, what does the word "better" mean in the question? Also, "better" in terms of what? The answer to the first question varies. The important thing to remember is that "better" is a relative term. Keep this in mind as you consider the questions regarding groups and individuals.
However, we have already answered the second question. We know the factors that we would like to see performed well. The answers to the second question are the six output variables that we described in Chapter 1. The variable of cohesiveness, by definition, cannot apply to individuals. However, the remaining five relate to the performances of both groups and individuals. We can define "better" in terms of each of these output variables.
Hence, we have created five questions that apply. We can ask the following: Between groups or individuals, which is
1. more productive?
2. more accurate?
3. capable of higher-quality solutions?
4. faster?
5. more satisfied?
These questions help us to understand what qualities are desirable when someone performs a task. We might like the job to be done quickly and with high quality, for example. The output variables give us good reference points for the term "better."
What Are "Tasks"?
There is a second aspect of the question "Are groups or individuals better at performing tasks?" that makes the question particularly vague. To what does the term "task" refer? What types of tasks can groups perform?
In order to answer these questions, scientists have suggested many "typologies" of group tasks. These typologies are systematic classifications that help focus investigations. We will use one such typology to organize our discussion. The classification system that we will use is based on one that Ivan Steiner (1966) proposed. His work is crucial to the topic of this chapter, and we will be describing it further. However, we will use a simpler set of terms to refer to each of these than did Steiner. Instead of using his technical wording, we will (with one exception) give each of the tasks a name relevant to the output variable most relevant to it. Group tasks include the following:
1. Productivity tasks. In productivity tasks, everyone in the group is doing the same thing. The outcome of a productivity task is the total of the individual members' products. For example, we might assign a three-person group the task of typing addresses on envelopes. One person types 200 envelopes, the second types 150, and the third does 100. As a whole, the group types 450 envelopes. Along with productivity, we will also evaluate the groups' performance according to its speed.
2. Coordination tasks. We also base the outcome of a coordination task on the work of all group members. However, it is not simply a combination of each individual's performance. Instead, a coordination task is something that the entire group must perform "together." For example, each step along an assembly line requires that a different person does a specific job. If one person is missing, the assembly work cannot be done. In addition, one slow worker will hold up the entire line. We call this a "coordination task" because the members must coordinate their actions for the group to be successful. We usually evaluate the performance of a coordination task in terms of speed.
As the assembly line example shows, a group's performance on a coordination task depends on the least competent group member. For instance, Harold, Frank, and Sue work on making a car. Frank works at a relatively slow rate. He is least competent at his job. No matter how quickly Harold and Sue put the rest of the car together, the car is not finished until Frank puts on the wheels. The group's speed, therefore, is determined by Frank.
3. Accuracy tasks. In contrast to the coordination project, the level of performance for an accuracy task depends on the group's most competent member. This occurs because people working on an accuracy task attempt to choose the best out of a set of possible options. The group should succeed if one of the members can perform the job well. Thus, the least competent group member need not affect the group's performance.
All accuracy tasks have an objectively correct answer. We can, however, make two distinctions between different subtypes of accuracy tasks. The first distinction is between accuracy tasks in which groups can and accuracy tasks in which groups cannot recognize whether it has chosen a correct answer by itself. In the case of accuracy tasks in which groups cannot recognize whether they are accurate, they need outside verification. Certain games illustrate the character of this subtype of accuracy tasks quite well. Perhaps you have played one of the many "survival game" exercises such as "Lost on the Moon" or "Lost At Sea." In these games, group members must prioritize supplies for a group of stranded travelers. The supplies include food, medical supplies, and other items that might actually help such explorers. They also include supplies such as alcohol which could actually hurt the travelers. According to survival experts, there is a true "best" answer. However, the players need to consult the guide to the game in order to find out if they have chosen the best solution. They do not know the right answer on their own. The guide gives groups outside standards by which the groups can measure their work.
There are other accuracy tasks in which the group itself can recognize which answers are best. Projects that scientists label "eureka-type" tasks are the most prominent in this category. Groups can solve these problems by using a sudden flash of insight on a group member's part. A good example of a "eureka-type" task is the problem of the missionaries and the cannibals:
On one side of a river there are three missionaries and three cannibals. They have a boat on their side that is capable of carrying only two of them across the river at one time. All of the missionaries and one cannibal can row. At no time on either side of the river can cannibals outnumber missionaries, or the missionaries will be eaten. The task is to get all of them across the river.
People generally attempt to solve this puzzle through endless trial-and-error variations that move people across and back over the river. However, this method does not work. The answer to the predicament involves a different, counter-intuitive move. In order to recognize the answer, a group member must have a flash of creative insight. Yet, once this insight has occurred, the group can know by itself if the answer is correct. (The "trick" to the cannibals and missionaries problem is to move two people back to the starting side of the river on some of the moves. People tend to dismiss this possibility. It seems to defeat the purpose. However, it is the only way to change the relative proportion of cannibals and missionaries on either side of the river so that all can cross safely.)
The second distinction is between accuracy tasks that include one stage and accuracy tasks that include more than one independent stage. By independent, we mean that any stage can be completed without having to know the answer to any other stage. For an example of the first subtype, a group may be assigned to the task of making a very complex mathematical computation. As an example of the second, a group may be asked to make a series of unrelated mathematical computations. For the group to be successful, it has to compute accurate answers in each computation.
Along with accuracy, we evaluate group performance on all of these tasks with objectively correct answers on speed.
4. Quality tasks. In contrast to accuracy projects, quality tasks have no objectively correct answers. The best example of a group involved in a quality task is a policy-making body in a large organization. It can create whatever policy it wishes. There is no verifiable standard that one can use to judge the group's decision. Hence, we cannot evaluate the "accuracy" of the outcome. Instead, we examine these tasks in terms of quality and speed. It is important to emphasize that we cannot equate the quality of a group's performance with the success of its decision. For instance, even if the policy that the organizational group chooses fails, we cannot assume that the group made the wrong choice. It might have been that conditions in the organization were very unfavorable. In that case, any available option would have failed.
Table 2.1 summarizes these types of tasks. For each task, the table includes a short description and lists the most relevant task output variables.
| Table 2.1 | Summary of group task types | |
| Type | Description Relevant |
Output Variables |
| Productivity | Each member does the same thing |
Speed |
| Coordination | Members must coordinate actions | Speed |
| Accuracy | Members choose best of set of options with objectively correct answer | Accuracy, speed |
| Quality | Members choose best of set of options with no objectively correct
answer |
Quality, speed |
What Is the Question?
The topic of this chapter is the relative capabilities of groups and individuals. We have asked "What is the question?" that experimenters can use to focus their research on this topic. Scientists began with the simple query "Are groups or individuals better at performing tasks?" It was soon clear that, although it was a good initial question, it was too vague. Theorists have been able to break it down into parts that clarify and sharpen the issues.
How, then, should we rephrase the question? Actually, our first, vague query becomes a series of questions. We need to ask for answers regarding all of the output variables and all of the task categories. For example, we should ask whether groups or individuals lead to
1. more productivity at productivity tasks? or more speed?
2. more speed at coordination tasks?
3. more accuracy at accuracy tasks? or more speed?
4. more quality at quality tasks? or more speed?
Our vision of how we can discuss the relative merits of groups and individuals is much clearer.
Now that we know the questions we need to ask, what are the answers? As this chapter progresses, we will be discussing research that reveals at least tentative answers.
However, we must first examine how scientists have attempted to answer these questions over the years. Amazingly, the first thing that early researchers discovered was that the series of questions that we have just developed was still too vague. They had to refine their examinations even further.
EARLY THEORIES AND RESEARCH
The question of whether groups or individuals are better at performing tasks is basic. It is so basic that it became one of the first issues that early social scientists examined back in the 1920s, when experimental research in the social sciences began to become prominent. Our hindsight allows us to view this research carefully. We now understand better some of the suppositions at work behind the experiments, as well as some of the faults of the work.
One of the faults of this early work is that it failed to consider some implications of the input-process-output model we discussed last chapter. For example, consider the hypothesis that the more people there are in a group, the better the groups' product will be. This claim may seem clear, but it is actually ambiguous. This is because as stated it only refers to input (group size) and output (group performance). It ignores the impact of group process on this relationship.
There are actually three different possible relationships between group size and group performance that can be proposed. These three differ from one another concerning the impact of group process. We will call these three possibilities wholism, reductionism, and for want of a better term the no-effect relationship. Let us describe each of these in turn:
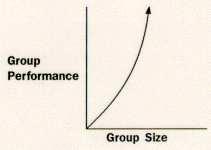
1. Wholism. Wholism is our name for the assumption that any whole is greater than the sum of its parts. Researchers who have the wholistic viewpoint believe that the experience of interacting with others leads people to perform tasks better than they would if they were performing alone. As a consequence, wholists maintain that actual groups should perform better than "aggregates" (combinations of individual people) of the same size. In fact, the concept holds that, as the size of a group increases, its performance will increase at an accelerated rate. We can show this relationship graphically in Figure 2.1.
FIGURE 2.1
2. Reductionism. Reductionism holds that the whole group is, at best, only equal to the sum of its parts. This happens if interaction runs smoothly. If interaction does not go well, a group's performance will be less than the sum of what each group member could have done alone. The larger the group, the greater the odds are that the group will have problems with interaction. Thus, the larger the group, the less well it will perform relative to an aggregate of the same number of people. Further, individual members will perform more poorly in a group setting than they would if they were working alone. We can show the relationship between performance and group size in Figure 2.2.
FIGURE 2.2

3. No-effect relationship. The third possibility is that interaction has no effect on group performance. Thus people will perform at the same level whether they are in a group or working alone. Consequently, the whole is equal to the sum of the parts. If this were true, groups would perform at the same level as aggregates of equal size. Figure 2.3 shows what the relationship between group size and group performance would look like in this case:
FIGURE 2.3
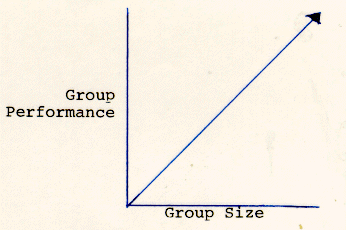
Note that in all three cases group performance improves as group size increases. However, the input-process-output relationships differ. In wholism, process adds to the improvement in group performance as group size increases. In reductionism, process suppresses the improvement in group performance as group size increases. In the no-effect relationship, process has no effect on group performance over and above group size.
Relevant Research
A series of early experiments claimed to support the wholist assumption. This work compared performances between individuals and groups and supposedly revealed that groups consistently perform better. We shall discuss two experiments that are representative of this early research.
Gordon's research. Gordon (1924) designed an accuracy task in which participants were to rank-order a set of weights by indicating which weight was 5 ounces, which was 10 ounces, and so on. The participants worked alone. Gordon then combined the participants' rankings into aggregates of 5, 10, 20, and 50 rankings. She next figured out the averages of the aggregates. Gordon called these averages the "group" judgment. Her results showed that the larger the aggregate, the more accurate the judgment.
Shaw's research. Shaw (1932) conducted an experiment in which she asked individuals and four-person groups to perform a series of accuracy tasks. The tasks were similar to the missionaries-and-cannibals puzzle described earlier. Shaw found that the groups had a higher proportion of accurate solutions than the individuals.
Conclusions
We can conclude from these two studies that, at least for accuracy tasks, groups perform better than individuals. The experiments appear to support the wholist assumption.
However, appearances can be deceiving. When we examine the experiments more closely, neither of them truly supports the wholist conclusion. As you will recall, wholists claim that interaction is partly responsible for groups performing better than individuals. Did the experiments of Gordon and Shaw reveal this interaction at work? For example, did Shaw show that it was through group discussion that groups were often correct regarding their accuracy task? The answer is "no." Neither experiment showed that the performance increases were due to any interaction among the members. The improved effectiveness seemed to be only the result of larger aggregates of people.
A closer look at Gordon's research. Recall that Gordon's groups did not interact. They were simply aggregates of people. Let us consider some implications of having different-sized aggregates work on this task.
When people make judgments such as those in Gordon's study, people tend to make random errors. In other words, people are as likely to overestimate as they are to underestimate the weights. In addition, there will be occasional judgments that are very far off the correct answer. These estimates may occur one out of every 10 times, for example. When they do, they significantly affect the average.
For instance, let us look at an aggregate of 10 judgments. The chances are that there will be one estimate that is very far off the correct answer. It is equally likely to be over or under the true weight. This one judgment will cause the average of the estimates to be substantially different from the correct answer. Some examples of numbers can illustrate this process. Say that the true weight of an item is 10 pounds. Ten people give estimates. Nine judge correctly and say 10 pounds. Only one person is wrong, but he says 20 pounds. This one incorrect answer is enough to throw the average off significantly. As you can calculate, just his one mistake brings the group average up to 11 pounds. This makes the group incorrect by 10 percent, even though only one member was wrong.
However, what happens as the aggregates get larger? Take an aggregate of 100 judgments. About 10 will be far off. It is likely that close to half of them will be on each side of the true weight. In this way, they can cancel out one another. For example, one member will say 15 pounds, but another will say only 5. Their average is 10 pounds. As such, it cancels out their mistakes. This process allows the average of an aggregate of 100 to move closer to the actual weight. The more estimates that we add to the aggregate, the more likely it is that poor judgments will compensate for one another.
As you can see, adding more judgments will improve the accuracy of the average. This is due to the nature of these kinds of judgments. It is not due to the fact that a larger group of people is involved. Indeed, Stroop (1932) found that he could use only one person and get the same results that Gordon did. He combined 5, 10, 20, and 50 judgments made by the same
person. His experiment yielded the same increase in accuracy as Gordon's did. It is possible to replicate this finding by simply flipping a coin. The more often you toss the coin, the closer the proportion of heads and tails comes to being equal. Think of heads as an estimate above the correct weight, and think of tails as a judgment that is too low. The action of the one coin will eventually equal out, just as one person's estimates will slowly average out toward the correct weight.
As should be clear, since Gordon's "groups" did not interact, her experiments could not possibly support wholism. All that they show is that the average of judgments made by larger aggregates of people is more accurate than the average of judgments by smaller aggregates of people.
A closer look at Shaw's research. In the case of Shaw's research, there was actual group interaction. Nonetheless, they still do not provide evidence in support of wholism.
As you will recall, the outcome of an accuracy task depends on the most competent member of the group. All it takes is one person who is correct, and the group will succeed. It follows from this idea that the more people who are working on a problem, the greater the odds are that someone will be competent enough to solve it. This is what happened in Shaw's study. Scientists have been able to show this phenomenon at work through a mathematical model.
Let us assume, for example, that the odds of a single person solving a certain problem are 40 percent. Thus if Joe Schmo were to try the problem, there would be a 40 percent chance that he would solve it and a 60 percent chance that he would not solve it. Now, consider what would happen if Joe Schmo and Sue Blue were both working on the problem. In this case there are four possible outcomes. One possibility is that both Joe and Sue could solve the problem. A second possibility is that only Joe could solve the problem. A third possibility is that only Sue could solve the problem. The last possibility is that neither can solve it.
Let us further assume that the "no-effect" relationship were true. If so, then the odds that Joe can solve the problem are unaffected by anything Sue says or does, and the odds that Sue can solve the problem are unaffected by Joe. This allows us to compute the odds of all four possible outcomes by multiplying the odds that Sue and Joe will or will not solve the problem. The odds of the first possibility, that both solve the problem, will be the product of the odds that Joe can solve the problem (.40) and that Sue can solve the problem (.40), which is .16. The odds of the second possibility, that only Joe can solve the problem, will be the product of the odds that Joe can solve the problem (.40) and that Sue cannot solve the problem (.60), which is .24. The odds of the third possibility, that only Sue can solve the problem, will be the product of the odds that Sue can solve the problem (.40) and that Joe cannot solve the problem (.60), which is also .24. The odds of the fourth possibility, that neither can solve the problem, will be the product of the odds that Joe cannot solve the problem (.60) and that Sue cannot solve the problem (.60), which is .36. Note that the sum of .16 and .24 and .24 and .36 is 1.00.
Now remember that the problem is solved if either Sue or Joe or both solve the problem. That possibility includes the first three possible outcomes. Thus if we add those three possibilities together (.16 + .24 + .24), we find that the odds that the problem is solved is .64. The probability that they will solve the problem (.64) is equal to 1.00 minus the odds that neither will solve the problem. Now given that the odds that neither will solve the problem (.36) is the product of the odds that Joe cannot solve the problem (.60) and that Sue cannot solve the problem (.60), it follows that the odds that they will solve the problem equals 1.00 minus (the odds that Joe cannot solve it multiplied by the odds that Sue cannot solve it).
This thinking can be extended for groups of any size. If a group consists of four members, and each member has a 40 percent chance of solving a problem and a 60 percent chance of not solving it, than the "no-effect" relationship leads to the prediction that the group will solve the problem 1-(.60 x .60 x .60 x .60) or 1-(.60)4 of the time, which turns out to equal .87. In general, we can compute these odds by using the following formula:
S= 1-Fm
(S = the likelihood that the group solves the problem; F = the likelihood that each member will fail to solve the problem; and m = the number of persons in the group.)
This model is called the Lorge/Solomon Model A. We will discuss the theory behind this equation in another section in this chapter. As we can see, the model shows how Shaw was able to get her results. The larger her groups, the greater the chance that at least one person could solve the problem. Sheer numbers brought the group performances up. Shaw's experiment was similar to Gordon's. Both researchers ignored the impact of group interaction. In doing so they were unable to evaluate the concept of wholism.
Wholism Reexamined
The real implication of wholism is not that larger numbers of people will perform certain tasks better than smaller numbers. Clearly, there are times when this idea is true. For example, a group of five people could certainly lift a heavy object better than one person. However, these kinds of aggregates do not really fit the concept of wholism. The real implication of wholism, instead, is that the interaction among the people in a group is important to performance. It is this interaction that should allow people in a group to perform better than the same number of people working alone. If a study could show that an interacting group performs better than an aggregate of equal size, that study would truly support wholism.
Therefore, evaluations of experiments such as Gordon's and Shaw's revealed that even our series of questions was still too vague for the study of the relative performances of groups and individuals. The experiments needed to distinguish between two possible explanations for improved group performance. Did the groups perform better because of aggregation or because of interaction? Scientists discovered that they needed to ask a revised question. They had to keep the following consideration in mind as they pursued their research: "Which is better at performing tasks--interacting groups of a given number of people or noninteracting aggregates of the same number of people?"
This is a very important distinction. Let us imagine that scientists find that aggregates always perform as well as groups. Then there may be no reason to take the trouble and expense to get people together to perform tasks. Instead, we could simply combine their individual products after they are finished working separately. This could save a great deal of time and energy. Further research studied this valuable distinction between aggregates and groups.
Groups Versus Aggregates
By the 1950s, researchers were performing studies designed to answer this revised set of questions. They kept in mind the distinction between groups and aggregates.
These researchers asked participants to perform tasks that were similar to the projects that the early researchers had used. However, they asked revised questions and used a different methodology. They did not compare the accomplishments of groups and individuals. Instead, the investigations compared the accomplishments of groups and aggregates. The aggregates were made up of noninteracting persons, and the group members interacted. Both were of the same number of people.
To judge the differences between groups and aggregates, researchers began using what are called "baselines." A baseline establishes a standard for comparing groups and aggregates. The standard consists of the performance that an aggregate of people would be expected to achieve. The Lorge/Solomon model is an example of a baseline. Researchers in the 1950s used the numeric outcome of the model as a standard for comparing groups and aggregates. For example, if an individual has a 40-percent chance of solving a problem, the model holds that there is an 87-percent chance that an aggregate of four people will solve it. Scientists looked at this percentage rate and realized that if interacting groups have more than an 87-percent success rate, they have supported the claims of wholism: Interaction has helped the groups perform better than aggregates of the same size. By contrast, groups that have less than an 87-percent success rate did its job less well than an aggregate could have, which supports the idea of reductionism: Interaction has made the groups perform worse than aggregates of the same size. Finally, if the groups have an 87-percent success rate, the same as same-size aggregates, then interaction has no effect on the groups.
In the following section, we will describe more current theory and research relevant to the impact of interaction on group performance. This work does not repeat the mistakes of the early researchers that we have just described.
CURRENT THEORIES AND RESEARCH
In particular, some of the more modern work incorporates the input-process-output model. An example is Steiner's (1966) theory of group performance.
Steiner's Theory
This theory includes four categories of variables. The first category of variables is task demands. These are input variables that correspond to the requirements of the job. For example, typists in a typing pool might have the productivity task of addressing a group of envelopes. The task demands are, for instance, that 500 addresses need to be typed within an hour.
The second group of variables is resources. These are input factors representing the knowledge, ability, skill, or tools that the members have at their disposal. In our example, these variables include the ability to type and adequate numbers of typewriters and envelopes.
The third group of variables is process variables. These include not only communication but all the actions that the group actually performs when it works on its assignment. These include actions that are both productive and nonproductive to finishing the job. For instance, some typists may work accurately and quickly; others may talk so much that their work suffers.
The fourth group of variables is group performance. These include whatever task output variables are relevant to the group's task. In our example, the relevant output variable is productivity. In our example, this would be the number of envelopes that the workers typed.
We can represent the four variables of Steiner's theory in Figure 2.4.
Figure 2.4 Input Process Output
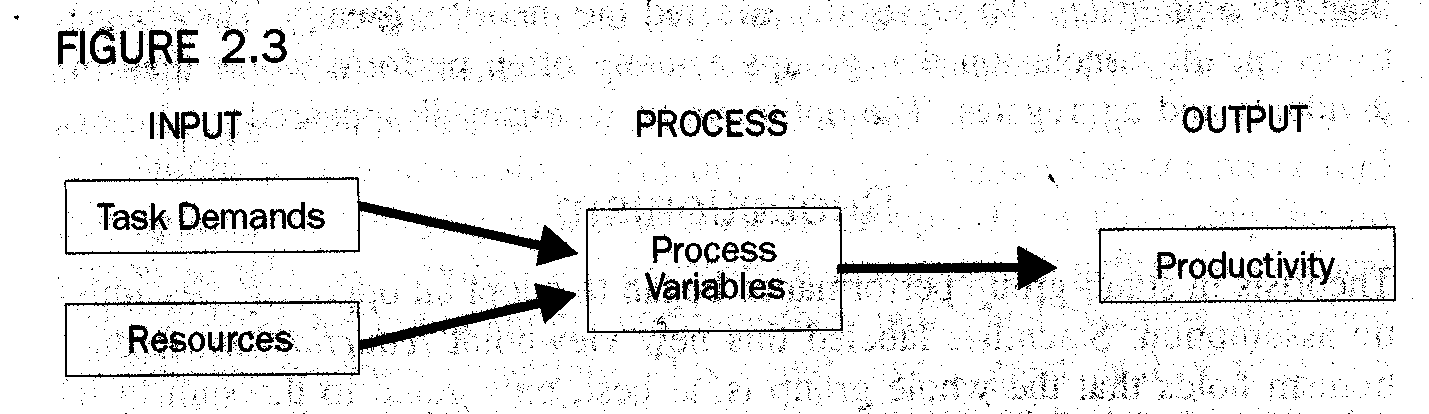
However, Figure 2.4 cannot show the crucial part of the theory--the relationship
among the variables. Let us examine how the variables relate to one another.
To begin, task demand variables determine the amount and type of resources that the group needs. For example, the typing group must complete 500 addresses in an hour. The group's resources could include five typists who are capable of completing 100 addresses an hour each. The group would then also need five typewriters, enough envelopes, and so on. If the group has all these necessary resources, it is possible for it to work up to its greatest capability. The typists could complete the task successfully. We would call this result full productivity.
However, it may be that the group cannot get the resources it needs. Perhaps it can only find four typists. Even if the typists do the best job they can, the group will only produce 400 typed envelopes in an hour. This work equals the group's potential productivity. This is the maximum it can possibly achieve with the resources it has. In other words, what potential does the group have, given its limited resources? Thus, full productivity minus loss due to insufficient resources equals potential productivity.
There are further relationships among the four variables. For example, productivity also depends on the process variables. Steiner labeled the amount of work that a group truly accomplishes as the group's actual productivity. This output relates to the ways in which the process variables function.
Actual productivity will equal potential productivity only if the process variables run smoothly. They run smoothly if they are adequate and appropriate for the job at hand. For instance, the typists might give full attention to the task, and all their interaction may be both relevant and necessary to complete the job. If this is true, actual productivity will equal potential productivity. The group will work up to its potential. Everyone does the best job possible.
However, Steiner believed that this rarely occurs. He theorized that the typists usually react naturally to a boring task. Their minds may wander, or perhaps they talk among themselves. If this happens, the process variables are faulty. Things do not run as smoothly as they could. Thus, actual productivity equals potential productivity minus losses due to "faulty" process.
As you can see, there is a reductionist assumption in this last claim of the theory. This is the important aspect for us. Steiner conceded that process variables can allow a group to reach the potential of its individual members. However, this happens only when process is optimum. Steiner's hypothesis is that this rarely occurs. Instead, he believed that group process is usually faulty. Interaction normally does not go as well as it could. This means that groups customarily do not reach the potential of individual members. The group holds members back.
We can see that Steiner agreed with the reductionist position. He gave no consideration to the possibility that the wholist view is correct. He did not believe that group process could lead to group performance going beyond what the sum of what the members could perform alone.
Is Steiner's theory correct? Can an interacting group never do a job better than an aggregate? Should humans ever perform tasks in groups?
Not surprisingly, the current answers to the above questions depend on the type of task and output variable that we consider. Once again, we are back to our series of questions. Now, however, we will also keep the distinction between aggregates and groups in mind.
You may have noticed by now that we have been ignoring the maintenance variables, such as group satisfaction. We will postpone our discussion of these variables for one more section. For now we will again focus on task variables as we discuss the various findings that we find valid today.
Productivity Tasks
As you recall, the outcome of a productivity task is the total of the individual members' products. The typing job exemplifies this idea. Each typist contributes his or her product to the group's total output. Let us examine how this process might work. For example, we might place five typists in five separate rooms. Working alone, each typist individually completes 100 addresses in an hour.
What happens if the typists work together as a group in one room? A wholist would predict that the group would type more than 500 envelopes. In contrast, a reductionist would theorize that the typists together would produce fewer than 500 addresses. Finally, an advocate of the no-effect hypothesis would expect that the group would type 500 addresses. Studies have shown that, in general, the reductionist would be right.
The Ringlemann Effect and Reductionism
A researcher named Ringlemann first noticed this outcome back in the 1880s. He found it during what was perhaps the first social psychological experiment ever performed (Kravitz and Martin, 1986). The details of the study are vague. However, it appears that Ringlemann had different numbers of people pull on a rope together. He measured the amount of force that each person exerted while pulling. Ringlemann's results are presented in Table 2.2.
Table 2.2 Ringlemann's Results
Number of Workers Total Performance Performance Per Worker
1 1.00 1.00
2 1.86 .93
3 2.55 .85
4 3.08 .77
5 3.50 .70
6 3.78 .63
7 3.92 .56
8 3.92 .49
As you can see, his results supported reductionist theory. The total performance
of his groups followed the reductionist curve for performance and group
size that we diagramed earlier. As the groups became larger, the productivity
per person dropped. In the century since Ringlemann's work, numerous studies
have replicated his early findings. These studies have involved many types
of productivity tasks.
Let us consider the implications of this "Ringlemann effect." We will use the example of the typists again. One typist can complete 100 envelopes in an hour. According to the Ringlemann effect, five typists working together may produce, for instance, 400 envelopes in an hour. The five typists together produce far more work than one typist alone could. Productivity of the group is greater than for one person. When we increase the size of a group that is doing an productivity task, we do increase "total" productivity. We also decrease the time it takes to get the job done. However, does all this support the concept of wholism? No. The group of typists shows that wholism does not work. Each typist's output has dropped by 20 percent because the group works together. Each one types only 80 envelopes instead of 100. Therefore, increasing the group's size leads to decreases in the productivity per person. The rate of speed at which each member works also goes down. Ringlemann's study demonstrated these conclusions clearly.
Explaining the Ringlemann Effect
Researchers have recently become interested in explaining why the Ringlemann effect occurs. Ingham, Levinger, Graves, and Peckham (1974) hypothesized two reasons for the effect.
1. Coordination. People working together have to coordinate their activities. This leads to problems in groups. The larger the group, the harder it is to achieve coordination. Let us go back to the task of pulling on a rope. How can we achieve maximum results for the job? A group of people must pull their hardest, at the same time, and in the same direction. It can be difficult to orchestrate such total coordination. The more people pulling, the harder it is to get everyone to work together smoothly.
2. Motivation. Working with other people on a strenuous task may lower individual motivation to work hard. We can assume that most people really do not want to exert themselves on a difficult task. Therefore, people may reduce their individual exertions when working in groups. They hope that other group members will make up for their weaker efforts.
Ingham et al. set out to discover which of these factors was responsible for the Ringlemann effect.
Relevant research. First, Ingham et al. replicated Ringlemann's rope-pulling experiment, with the same results. Second, they set up a situation in which they could distinguish between the coordination and motivation factors in order to determine which one best explained the Ringlemann effect. In one phase of the study by Ingham et al., participants believed they
were working with a group when they were actually working alone. In this way, researchers could measure the effect of the motivation factor. They could see if people work less strenuously when they think they are working with others, as opposed to when they think they are laboring alone.
To begin, the scientists asked subjects to pull on a rope as hard as they could. The participants worked alone and were blindfolded. Next, each participant returned and found a group of other people also beside the rope. The researchers said that the group was to pull on the rope together and that all of them would be blindfolded. In reality, the other people in the group were confederates working with the researchers. The participant once again pulled on the rope alone. The researchers took great pains to make the participants think that they were pulling as members of groups. The confederates groaned, complained about the difficulty of the task, and moved the rope left and right. It appeared to the blindfolded subject that others were also pulling on the rope. The trick seemed to work. Very few participants guessed that they were actually working alone.
The results of the experiment supported the motivation explanation. People exerted themselves at a certain level when they worked alone and also thought that they labored alone. In contrast, when the participants thought that they were working in a group, their exertion level dropped even though they were still actually doing the job alone.
Other experiments have also supported the motivation explanation. It is true that coordination problems can hurt group productivity on productivity tasks. However, it has become clear that most of the losses in performance per person happen because each person works less as the group size increases. Scientists have labeled this tendency social loafing.
A great deal of research has been applied to the topic of social loafing. It appears that such loafing occurs primarily when no one can distinguish each member's personal contribution to group output. In these circumstances, members are not afraid of being criticized for low productivity. In contrast, less social loafing happens in situations where the group can distinguish and evaluate members' performances separately. In fact, a recent study by Stroebe, Diehl, and Abakoumkin (1996) found the opposite of social loafing, social facilitation, to occur in this circumstance. Participants turned a wheel with a brake giving it strong resistance as fast as they could for 10 minutes alone and then, after a rest, for 10 minutes in groups of two. A computer displayed each person's performance for both to see. When two people who had equal individual performances worked together, they increased their individual performance by more than 5 percent. The researchers believed that the display led to a competition between the two, increasing their effort. When two people who had unequal individual performances worked together, the weaker of the two increased their performance by more than 10 percent. In this case, Stroebe et al. thought that the weaker wanted to perform as close to the level of the stronger as they could.
There are other factors that seem to lower the instances of social loafing. For instance, group members exert themselves when they consider the task particularly important or challenging or when they consider the group's total performance important. They also work harder when they think they have something unique to contribute to the group. (See Karau & Williams, 1993, for a review.)
Coordination Tasks
As we have noted, the outcome of a coordination task depends on the performance of the least competent group member. The group must follow whatever pace this member sets. We have seen how productivity tasks follow the assumption of reductionism. This assumption also holds true for coordination projects.
Reductionism and Coordination Tasks
Let us examine how reductionism applies to coordination tasks. The probability that a group will contain an incompetent member increases as the group's size gets larger. Thus, it is likely that bigger groups will fail more often than smaller groups. In fact, the Lorge/Solomon Model A formula shows this idea vividly. To repeat the previous example, let us imagine that both Sue Blue and Joe Schmo have a 40 percent chance of completing a task and a 60 percent of not completing it. Again let us assume that interaction with one another has no effect on their performance. Now remember that in coordination tasks the entire group fails if any one member cannot complete it. Using the same logic as before, the odds that Sue and Joe will not both complete the task is:
S= 1-Cm
(S = the likelihood that the group complete the task; C = the likelihood that each member will complete the task; and m = the number of persons in the group. Note how C, the odds that each member will be successful, replaces F, the odds that each member will fail, in the context of coordination tasks.)
In this case, 1-C2 equals 1-.402 or .84. With a group of four people having the same skill level as Sue and Joe, the odds of the group failing will increase to nearly 98 percent.
Frank and Anderson (1971) did an experiment based on this reasoning. They asked groups of two, three, five, and eight members to perform nine tasks. The projects required that group members generate ideas. For example, a group might write down three arguments for, and three arguments against, legalized gambling. The researchers made the project into a coordination task through their instructions. Each group member had to work alone, but the group could not move on to another task until all members had finished the previous question. As you would expect, the larger the group, the longer it took to finish all nine tasks. The groups worked just as the Lorge/Solomon odds predicted.
Accuracy Tasks
As you will recall, accuracy tasks have objectively correct answers. Earlier we made a distinction between two types of accuracy tasks; those that consist of one stage and those that include more than one stage. We will consider each in turn.
One Stage Accuracy Tasks
We have already described the assumption that a group's outcome on accuracy tasks depends upon the group's most competent member. Remember that, as long as one person can perform the task, the whole group has succeeded.
Several scientists proposed this idea in the 1950s. The most notable of the researchers were Lorge and Solomon (1955). We have already discussed their formula regarding the odds that a group can complete a task given that one of its members can solve it. Now we turn to the theory behind this equation. Their theory, called Model A, is quite simple. We can diagram it as in Figure 2.5.
FIGURE 2.5
Input Process Output
MEMBER'S
COMPETENCE-------------->
GROUP
INTERACTION------------->
ANSWER
If the group has a competent member, it will get the correct answer. Interaction
serves only a limited function. It simply allows a competent member to
inform the other members of the correct solution. Interaction serves such
a limited purpose that we can eliminate it when we predict the probability
of the group succeeding. The group will have the same odds of getting
the answer whether or not its group members interact.
Essentially, the odds that a group will find the correct solution are the same as the odds that it contains a competent member. If we know the likelihood that any one member will know the answer, we can use the Model A equation to predict whether a group of any given size will solve a problem.
Studies using Model A. We have already seen how Model A can serve as a baseline for research. It can help researchers compare various scientific assumptions that refer to how groups function when they perform accuracy projects.
One implication of Model A is that the larger a group, the better it should perform an accuracy task. Frank and Anderson (1971) altered their study of coordination tasks in order to examine this issue. To do this, the experimenters instructed some groups to move on to another problem when any group member finished the previous question. As expected, the larger the group, the faster it finished all the questions. This was in contrast to the groups performing coordination tasks, where the larger groups were slower.
Cummings, Huber, and Arendt (1974) asked groups of various sizes to perform the "Lost of the Moon" survival game. Each participant made a list that prioritized the available supplies. Participants then formed groups, and each group made another list that prioritized the supplies. Cummings et al. found that the larger the group, the more accurate its rankings tended to be.
However, this finding does not tell us why larger groups perform better. Was it because of interaction among members, or merely due to more people working on the task? Researchers need to compare accuracy group performance to the predictions of Model A to find out. For example, a group may perform just as Model A predicted that it would. If this happens, the group is behaving like an aggregate. It is performing at the level of its most competent member. Interaction is having no effect on the odds that the group is successful. On the other hand, actual group performance may be lower than Model A's calculation. The group is performing at a level worse than would its best member working alone. In that case interaction is hurting the group's effectiveness. The group's actions support the concept of reductionism. A third possibility is that the group might instead have an outcome that is greater than Model A's estimate. The group is performing at a level better than its best member working alone. If this happens, interaction is helping the group's performance. This supports the idea of wholism.
What were the actual results of the studies that used Model A to estimate accuracy tasks? Most experiments showed groups to perform equal to or lower than Model A's prediction. The findings supported reductionism.
For example, researchers have performed many studies using "Lost on the Moon" and similar survival games. In general, each group's list was more accurate than the average of the individual member's lists. In a great majority of cases, however, the group's list turned out to be not as accurate as the one made by its most accurate member. These groups did not take full advantage of their most competent member's knowledge. Such a finding is consistent with reductionism.
Assumptions of Model A. Why does this occur? Let us look at two assumptions implicit in Model A in order to answer this question.
The first assumption is that only the abilities of the group members determine the accuracy of the group's decision. Therefore, a group with no competent members will fail. This is true no matter how large the group is or how well its members interact.
The second assumption is that a group with a competent member will adopt that member's decision. The model assumes that other members come to realize that the competent member is correct or that they allow the competent person to persuade them.
Research. Scientists have performed many experiments to evaluate whether these two assumptions are correct. Johnson and Torcivia (1967) performed a study that is a good example of research into the Lorge/Solomon Model A. They asked participants first to perform the following "horse-trading" problem individually:
A man bought a horse for $60 and sold it for $70. Then he bought it again for $80 and sold it one more time for $90. How much money did he make? $0? $10? $20? $30? [The correct answer is $20. Add up the total spent and the total received. Then compare the two.]
The experimenters then took the participants and assigned them to one of the six following "conditions":
1. R = Individuals who previously got the right answer.
2. W = Individuals who previously got the wrong answer.
3. RR dyads = Dyads, or two-person groups, in which both members had
previously gotten the right answer.
4. RW dyads = Dyads in which only one member had previously gotten
the right answer.
5. WW dyads (same) = Dyads in which both members had previously
gotten the same wrong answer.
6. WW dyads (different) = Dyads in which both members had previously been
wrong, but had chosen different wrong answers.
After they assigned the participants to one of the conditions, the researchers asked the participants to perform the task again. The participants were not told whether their first answer had been correct.
The results are in the following Table 2.3. The table shows the percentages of those individuals or groups who got the right answer on their second try.
Table 2.3 Johnson and Torcivia Data
Condition Percentage Correct Answers
RR dyads 100
R individuals 96
RW dyads 72
W individuals 9
WW dyads (same answer) 10
WW dyads (different answer) 8
What do these findings mean? Immediately we can see that the previously
right people, the RR and R groups, continued to be correct. In contrast,
the groups with two wrong people, the WW groups, performed no better than
a single wrong person, the W condition. Thus, two incompetent people are
no better than one incompetent person. They cannot help each other reach
better decisions.
These findings support Model A's first assumption. A group really has to have at least one competent member. The results from the groups of two people who had different wrong answers, the WW dyad (different) condition, particularly support this implication from Model A. The researchers thought that a dyad composed of members with different wrong answers might lead the partners to discuss the problem more than dyads who had the same wrong answer. After all, they had something to disagree about. Maybe that could make them finally come to the true answer. However, this did not occur. As we can see, a competent person is very important for completion of an accuracy task. Interaction does not seem to help incompetent people come to correct conclusions.
These findings do not support Model A's second assumption that groups will always adopt a competent member's accuracy. In other words, if Model A is correct, a competent member will always be successful in persuading other group members to the correct answer. We can look at the results of the RW dyads to evaluate this assertion.
If the second assumption of Model A were correct, the R person would always be able to point out the correct answer convincingly to the W person. This would mean that the RW dyads would have given the correct answer all of the time. Looking back to the table of research data, however, we can see that the RW dyads had correct answers only 72 percent of the time. Truth did not always win out. Hence, the second assumption of Model A is faulty. The competent person did not always persuade the other group member.
Nevertheless, these findings show that the R member was successful at persuading the W member more often than not. The statistics show that the R person was better at persuasion than the W person was. We can see this if we compare the actual results with what should have occurred, statistically if W and R were equally successful at persuading each other.
Let us first look at the table of research data to determine what should have occurred if W and R were equally persuasive toward one another. As the numbers show, in their second opportunity, R people working alone were correct almost 100 percent of the time. In contrast, W participants working alone were right only about 10 percent of the time. If W and R individuals had been equally able to persuade each other, the percentage of correct RW dyad answers would have been halfway between the results for W and R individuals. This would have been about 55 percent.
This is not what happened, however. Let us now turn to the actual results. The numbers show that, instead of 55 percent, the actual amount of correct answers for RW groups was 72 percent. This means that the previously right participants succeeded in persuading their partners far more often than those who had been previously wrong.
Still, a success rate of 72 percent is a long way from the almost perfect performance of the R and RR conditions. Model A's second assumption has some validity but is nevertheless faulty. The competent group member does not always persuade other group members.
Conclusions-assumptions research. What do the two Model A assumptions mean for group performance? Research has supported the first assumption. A competent person is essential for accuracy tasks. This capable person can perform as well in an aggregate as he or she does in a group. Therefore, group interaction does not help a competent person's performance.
Studies have shown that the second assumption is faulty. It is not guaranteed that groups will listen to their most competent members. Thus, interaction often makes it less likely that a group will reach the best solution for these kinds of tasks.
Assumptions and reductionism. As we can see, Model A does provide a suitable baseline for research into the question of whether groups operate according to wholistic or reductionist viewpoints. Groups that operated below the Model A estimates did reveal reductionism at work. Such groups either lacked competent members, or there were problems with whether the capable individuals were able to persuade the other group participants.
We saw the second of these problems in the RW dyads in the Johnson and Torcivia study. Do we know why this problem might have developed, however? Why is it that groups do not always listen to the most competent group member?
We can examine this question further through a later experiment by Zaleska (1978). This study revealed a great deal about how group members actually persuade one another when they work on accuracy tasks.
In the experiment, university and trade school students attempted the "horse-trading" problem. They also rated their own confidence in their answers. Only 33 percent of the university students and 27 percent of the trade school subjects were correct. Next, the researchers put the participants into groups. Each group had one member who had previously been correct. The groups discussed the problem. The experimenter measured the amount of talking by each group member. The last phase of the study separated the group members again. Each person then made a second attempt to solve the problem. The subjects rated their own confidence again and also rated the levels of confidence that they thought the other group members had.
It turned out that, in both the university and trade school student groups, the most talkative group member was generally the most persuasive. In the sample of university students, the most talkative person tended to be competent and was able to persuade others of the right answer at least some of the time. As a result, the percentage of university students who gave the right answer on their second try rose to 50 percent. In the sample of trade school students, the talkative group member was wrong more often than not. As a result, the percentage of trade school students who were correct on the second try fell to 23 percent!
It appears that the most talkative group member is the most persuasive in groups. The problem is that this member is not necessarily the most competent. This finding accounts for why group performance in the studies is lower than Model A predicts. Interaction can lead to correct answers for accuracy and tasks if the talkative, persuasive group member is wrong.
Multiple Stage Accuracy Tasks
Thus far we have considered accuracy task with just one stage. For example, people performing the horse-trading problem need to make one judgment, the amount of money that was earned, and then they are finished. However, there can be accuracy tasks that include more than one independent stage. By independent we mean getting the answer to one stage has no effect on getting the answers to other stages. Perhaps a group needs to take a multiple-choice exam, where each question is unrelated to each other. As we shall see, analysis leads us to form unique conclusions about multiple-stage accuracy projects. Our conclusions differ from those we reached concerning single-stage tasks.
Conditions of Multiple-Stage Accuracy Tasks
Types of people. Consider a two-stage task with each part operating according to the Lorge/Solomon Model A. There are four types of people who could be working on the project:
Type I people are able to complete both parts of the task.
Type II people can complete only the first part.
Type III people can complete only the second part.
Type IV people cannot complete either part.
What is the probability that a group will solve each stage of a task? We assume that it is equal to the likelihood that the group has a member who is competent enough to complete each section. There are two conditions under which a group can solve the problem. These circumstances involve combining the right types of members to do the job.
Types of conditions. The first condition is that a group can solve the problem if it has at least one Type I member. The second condition is that a group can complete the task if it has at least one member from both Type II and Type III. This second possibility only works if the group organizes itself well. Good organization allows the Type II members to concentrate on the first part of the problem while the Type III members work on the second part of the problem.
We can hypothesize that the second condition would produce a group that works faster than the first condition. Remember that the stages are independent, so that different group members can work on each at the same time. Since more people are working on the problem in the second condition, the group will finish faster. In other words, the Type II and Type III people can work simultaneously, while the Type I person has to work sequentially on each part of the problem. This results in another possibility. Imagine that a group with a Type I person also has a Type II member. In this case, the Type II person can work on the first part while the Type I person works on the second part. Such a combination of people would also speed up the group.
The point of outlining these conditions is to show that there are times when a multiple-stage accuracy task is best performed by a group, rather than by a competent individual. This can happen only if the group has members with the prerequisite abilities. Also, the group must be able to organize itself properly. If the group fulfills all of these requirements, it can perform as accurately as and faster than its best individual member. Members must plan the group's organization through interacting. Therefore, interaction in this case can be a positive thing. It is through successful interaction that the group may be able to perform a multiple-stage accuracy task as well or better than its most able member working alone.
Finally, we find a task to which the wholistic perspective can apply. Of course, the wholistic prediction can only come true if the group has the proper mix of competencies. For example, a Type I person in a group with only Type IV people would be better off working alone.
Various studies have revealed how the wholistic viewpoint applies to multiple-stage accuracy tasks.
Model B and Multiple-Stage Accuracy Tasks. Lorge and Solomon have applied Model A to each part of a multiple-stage accuracy task. They have labeled the combined outcome "Model B." This model serves as a baseline for research into multiple-stage projects. Model B assumes that social interaction neither helps nor hurts group performance of a multiple-stage assignment. The model also predicts that a group will succeed at a part of the task if any of its members can complete that part. In these ways, Model B is similar to Model A. In addition, Model B assumes that groups have optimal organization and that each member works at a part of the task that he or she is capable of doing.
Experimental results show that Model B overestimates actual group performance of projects. As you will recall, this was also true for Model A and single-stage accuracy tasks. Apparently, groups do not organize themselves optimally. However, groups did tend to perform multiple-stage problems much better than Model A would predict. This shows that groups did take advantage of at least some of the opportunities that organization can give them. We can conclude that it is correct for scientists to apply the wholistic perspective, in some ways, to these tasks.
Laughlin and Johnson research. A study by Laughlin and Johnson (1966) is representative of research that has used Model B to examine multiple-stage accuracy problems. The experimenters gave participants a test. The test had the participants identify synonyms, antonyms, and analogies. The researchers used the test results to classify the participants according to their ability at the task. Each participant received the rating of high (H), medium (M), or low (L). Participants then took the test again. This time the researchers placed each person in different test conditions. The participants were either alone again, or they were in dyads that combined all of the different abilities. The research used the following nine conditions: H, M, L, HH, HM, HL, MM, ML, LL. The test had a possible score of 148 correct answers. The results were as follows:
HH - 126.29 HM - 84.17 LL - 54.35
HM - 114.12 M - 76.53 L - 48.06
H - 95.24 ML - 74.41
HL - 92.94
How can we interpret these results? Consider this a task with 148 parts.
Each person is able to execute some of the parts. The results for the
H, M, and L participants represent the number of parts that each type
can perform on average. For example, the average H type of person can
complete 95.24 parts out of the 148 possible. It is unlikely that the
sections that any two members can perform will completely overlap. In
other words, each member of the dyad should be able to accomplish some
things that the other member cannot. This is true only if the members
have some degree of competence. If competency wins out, however, we assume
that dyads should perform better than individuals.
Wholism and competence. Did the results of the Laughlin and Johnson study support this wholistic idea? The answer is that in some ways they did and in some ways they did not. The key phrase is "if competency wins out." Wholism can work only if group members are capable. For example, the study did find that subjects who worked with others of H or M ability did have a better score than they would have if they had worked individually. One dyad condition particularly supported the wholistic viewpoint. Dyads combining H and M subjects created a higher score than the H participant would have gotten working alone.
Nevertheless, wholism does not function well when competency is a problem. Group members have to have some ability at the task. For example, H and M subjects who were paired with an L participant did slightly worse than they would have if they had worked alone. In these cases competency did not necessarily win out. Other findings also limited the wholistic conclusion. For instance, H individuals and HL dyads had better scores than MM partners did. It appears that high competency, as opposed to medium competency, is still the most important factor in group performance.
Quality Tasks
A quality task is one with no objectively correct answer. As such, it is difficult to investigate scientifically. There are two basic ways to evaluate groups working on quality projects. The first way is to judge the subjective quality of the group's outcome. The second method is to evaluate the manner in which the group goes about solving the problem.
Do groups or individuals perform quality tasks better? There is no clear answer to this question. The answer is dependent on a greater many factors. In later chapters we will discuss theory and research relevant to some of these factors. This will give us an idea about what groups need to do in order to make higher quality decisions than would individuals.
For the time being, rather than talking about how well groups perform quality tasks, we will discuss theory and research attempting to predict what decision groups will make when performing these tasks.
Mathematical Models for Policy Tasks
In this chapter we have described how scientists have worked on models to predict group performance. For example, the Lorge/Solomon Model A is a mathematical equation to predict the odds that a group will solve a single-stage accuracy task. It predicts by using the odds that each member will perform the task successfully and by assuming that interaction has no effect on these odds.
Scientists have attempted to provide mathematical models for quality tasks that are similar to the Lorge/Solomon Model A. Their research continues the work on modeling of group performance. The difference between an equation such as the Lorge/Solomon Model A and an equation to predict quality task decisions is significant. Model A is relevant to circumstances in which a problem has a correct answer. In contrast, a quality task has no "right" solution. Groups making these decisions attempt to combine individual attitudes into a group opinion.
With this in mind, what can mathematical models predict about quality task groups? They can mathematically represent the way a group creates the necessary combination of opinions. The models that we will describe attempt to do this.
Social Decision Schemes
Davis's interpretation. During the 1960s and early 1970s, scientists researched what we now call social decision schemes. Davis (1973) wrote an essay on this research in which he considered many schemes to represent group decisions in quality tasks. He revealed, for instance, how groups have explicit schemes as part of their decision-making rules. For example, most clubs and congresses work by majority rule. Juries often require unanimous votes. The League of Women Voters attempts to reach a consensus through a testing rule in which policy statements are tested until one emerges that nobody finds objectionable.
Davis also considered groups that do not have explicit decision schemes. He claimed that we can view such groups as having implicit rules that operate in a manner similar to explicit rules. Davis worked to create a general mathematic formula that he could apply to these overall, implicit rules.
Davis's model. Davis attempted to develop a model that could, in effect, represent the impact, or weight, of each group member's prediscussion opinion. He wanted to show how these individual opinions would affect the group's postdiscussion decision. As did Lorge and Solomon with Model A, Davis assumed that communication functions only to reveal each member's opinion. Once the members communicate their opinions, the arithmetic formula could predict the group's outcome. His model would show how the opinions of members combine to result in the group's decision. Davis did not doubt that opinions can change during group conversation. He claimed, however, that accounting for this change in mathematic equations was unnecessary. The model merely needed to weigh the impact of the successful persuader's opinion more highly than the other group members' opinions.
Figure 2.6 diagrams the decision-making process in quality tasks from the standpoint of social decision scheme theory.
FIGURE 2.6
Input Process Output
INDIVIDUAL
PREDISCUSSIONAL---|
OPINIONS |
|----->INTERACTION------->GROUP DECISION
SOCIAL |
DECISION-----------------|
SCHEME
The following example shows how Davis's idea would work. Two people must decide together how much they like a television program, using a scale of 1 to 9 to show their opinion. Kim's prediscussion opinion was a 4. Ramon's prediscussion opinion rated the show a 6. The two met and talked about the program. Their postdiscussion opinion was 5.5.
What process led to this outcome? One way to explain it is to assume that Ramon persuaded Kim to change her opinion, so that Kim's final opinion was more similar to Ramon's. The social decision scheme, however, would weigh Ramon's opinion as three-fourths responsible for the group decision. Davis used this idea as he created his mathematical model. In essence, in the social scheme that Ramon and Kim spontaneously created, the rule was that Ramon's opinion had more impact on the group decision than Kim's opinion. The resulting scheme would be:
3/4 (Ramon) + 1/4 (Kim) = decision
In this circumstance, the numbers would be:
3/4 (6) + 1/4 (4) = 5.5
The Uses of Mathematical Models
In general, mathematical models describe and predict decision making well. They do not, however, explain how groups make decisions in quality tasks. They are also not particularly concerned with what occurred during the discussion. What caused Ramon's opinion, for example, to have greater weight than Kim's? The equation does not show this. Further, we can represent any decision process by some arithmetical model, but we have no way to evaluate the mathematical approach as a whole.
We can evaluate, however, whether specific equations are better for certain purposes than others by examining the mathematical predictions of several schemes and comparing them with the results of actual group decision making.
Predicting jury verdicts. Mathematical models have been very helpful in representing jury verdicts. Scientists have performed a great deal of research using mock juries, groups of participants who receive information about a crime and are then asked to come to a verdict.
Research has discovered a pattern of outcomes for mock juries: The side that the majority favors before group discussion becomes the verdict about 90 percent of the time. For example, a majority of the people on a 12-person jury individually think that a person is guilty before they start to deliberate. In such a case, the jury will reach a "guilty" verdict 90 percent of the time. In contrast, the minority successfully persuades the majority only about 5 percent of the time. During the other 5 percent of the time, the 12 people cannot reach a decision, resulting in a "hung jury."
Scientists who employ mathematical models would use these test outcomes as a base of comparison for their work. They would propose a set of decision schemes, and then they would see which model best predicted the results of this research. Each scheme would predict the odds that a jury would decide "guilty" or "not guilty." The models use the proportion of jury members having prediscussion opinions on either side. Here are three possible models:
1. Majority model--bases its odds for an outcome on whether a plurality of jurors supports the outcome.
2. Proportionality model--bases its odds that the jury will choose an option upon the proportion of jurors who support the option.
3. Equiprobability model--holds that all alternatives, as long as any member supports them, have an equal chance, or probability, of being the outcome.
Table 2.4 shows how the models predict that a 12-member jury will behave. In the diagram, "Yes" stands for "guilty," while "No" stands for not guilty." Table 2.4 shows the odds that the equations provide.
Table 2.4 Social Decision Schemes
Prediscussion Opinion Majority Model Proportionality Model Equiprobability
Model
Yes No Yes No Yes No Yes No
12 0 1.00 .00 1.00 .00 1.00 .00
11 1 1.00 .00 .92 .08 .50 .50
10 2 1.00 .00 .83 .17 .50 .50
9 3 1.00 .00 .75 .25 .50 .50
8 4 1.00 .00 .67 .33 .50 .50
7 5 1.00 .00 .58 .42 .50 .50
6 6 .50 .50 .50 .50 .50 .50
5 7 .00 1.00 .42 .58 .50 .50
4 8 .00 1.00 .33 .67 .50 .50
3 9 .00 1.00 .25 .75 .50 .50
2 10 .00 1.00 .17 .83 .50 .50
1 11 .00 1.00 .08 .92 .50 .50
0 12 .00 1.00 .00 1.00 .00 1.00
As you can see, the majority model comes closest to the actual results
of our example. Of these three models, it best predicts the decisions
that a mock jury would make. The majority model, however, does miss those
circumstances in which the minority successfully persuades the majority.
As we saw in our example, the minority was successful 5 percent of the
time.
THE EFFECT OF GROUP SIZE ON GROUP PROCESS AND MAINTENANCE
Let us summarize what we have covered in this chapter up to this point. We started with the vague question "Are groups or individuals better at performing tasks?" We then analyzed and clarified that question by taking into account the various group tasks and output variables that are possible. We also focused the question by noting the difference between aggregates and groups.
This distinction between aggregates and groups is very important for scientists doing research into this topic. The experimenters realized early on that comparing an individual's performance with a group's accomplishments was not really a good way to answer our question. They really wanted to know whether an interacting group performed better or worse than the same number of people working alone. Therefore, the research actually needed to compare the effects of increased group size to the effects of increased aggregate size. This gave a better picture of how well groups could do.
Beginning in the 1950s, experimenters focused on the differences between aggregates and groups. This research had three potential outcomes. One possible outcome was that an increase in group size led to better performance than the same increase in aggregate size. If this occurred, interaction had helped the group's accomplishments. This finding supported the concept of wholism. A second possibility was that an increase in group size led to worse performance than the same increase in aggregate size. This meant that interaction had hurt the group's outcome. Such a result supported the idea of reductionism. The third potential finding was that an increase in group size led to the same performance as the same increase in aggregate size. Thus, interaction had no effect on group outcome. This was the idea of Model A. When we say "same increase," we mean from original size to the same increased dimension. For example, an aggregate of five people and a group of five people both increase to six people.
We have explained the experiments in detail. In a nutshell, researchers found that groups perform worse than same-size aggregates in most cases. The exceptions were when groups worked on multiple-stage accuracy or quality tasks. With this type of project, groups were more successful than aggregates, in some situations.
Up to this point, we have used the issue of group size only as a tool. It has helped us to compare the relative performances of groups and aggregates. However, the issue of size is important in its own right. Indeed, we can view it as a logical extension of the very first question that we posed. Instead of asking if many people perform better than one person, we can get more specific. For example, do two people perform better than one? Would three people do a superior job than two? The examples can continue in the same fashion.
What have researchers found out about the effects of group size? The answers are consistent with our earlier findings. We will oversimplify them here because what we need are the essentials of the findings. Again, quality and multiple-stage accuracy are exceptions to what we are about to outline.
In general, increases in group size lead to five outcomes. Larger groups had the following:
1. more total productivity; however,
2. less productivity per person; and
3. increased odds that a group member will propose an accurate answer;
however,
4. greater odds that the entire group will not accept an accurate answer;
and finally,
5. slower work.
As you can see, comparing outcome one with outcome two, and outcome three with outcome four, shows the ways in which the advantages and disadvantages of increased group size can mirror each other.
Greater group size affects multiple-stage accuracy tasks differently. As noted earlier, the larger groups working on multiple-stage accuracy tasks will have increased odds of finding the correct answer to a problem. (However, with multiple-stage tasks, increases in size can lead to greater odds that the entire group will not accept an accurate answer.) In addition, the group should work faster. Both of these outcomes can occur only if the group is well organized, however. With quality task groups, larger groups will work more slowly than smaller groups. However, the bigger groups are more likely to reach a consensus that is satisfactory to all concerned.
The Maintenance Variable of Satisfaction
As we have discussed group size, we have begun slowly to refer to maintenance variables. We have mentioned elements such as whether group members accept an idea or find the idea satisfactory. Up to this point, we have not described the more social side of the research into groups and aggregates. Now we will do so. We can use our summary of how group size affects performance to begin a further examination of maintenance factors.
Group size has a particularly marked effect on group member satisfaction. The major reason for this is that there is a relationship between member communication and satisfaction. The greater opportunity that people have to communicate in groups, the more satisfactory the group experience will be for them. This works up to a point. We emphasize "up to a point" because the opportunity can become so great that it turns into an obligation. This obligation can make people uncomfortable. We also highlight the idea of "opportunity" because people may choose not to talk in a group. Even so, they can remain satisfied because they know that their silence is due to their own choice and not the result of factors beyond their control.
We need to keep these two highlighted ideas in mind as we examine the relationship that exists between group size and satisfaction. Communication "opportunity" and increased group size "up to a point" are important ideas in the following sections. They will help us immensely in explaining the group size/satisfaction correlation.
Group Size and Communication
As the size of a group increases, the relative opportunity that members have to speak decreases. They get less "talk time" apiece. If each member spoke for an equal amount of time, it would be easy to predict talk time. You would simply use the reciprocal of the number of group members. For example, if a group had four members, each would take one-fourth of the time. In a group of eight, each person would communicate one-eighth of the whole discussion. It would be the same with different groups. Large groups would give members little, though still equal, time to communicate. This alone would lower satisfaction as groups became larger.
However, in reality, groups do not allocate their talk time evenly. Up to a point, this fact is actually good for group task performance. Competent members should speak more than the less able members. However, any group member may make a useful contribution. All members should get equal opportunities to speak. This is particularly the case with quality projects. It is desirable that there be a great diversity of opinion among group members engaged in such a task because diversity can bring out creative solutions to problems.
Unfortunately, real groups rarely are able to hear all the opinions of their members. Further, it turns out that as group size gets larger, the distribution of talk time gets more uneven. Studies have shown that the most talkative members communicate almost as much in large groups as they do in small ones. This is at the expense of less talkative members, who receive even fewer opportunities to speak as the group gets bigger.
Bales, Strodtbeck, Mills, and Roseborough (1951) conducted a study that revealed the extent of this increase in discrepancy between talkative members and less vocal members. Later in this book we will be discussing Bales's work in great depth. For the time being, it is sufficient that you know his general research method. Bales's study involved students who would meet periodically in groups to work on "human relations" problems. The groups were of various sizes. This study is an example of the "content analysis" research method we described in Chapter 1. Observers watched them as they worked, content analyzing the amount and type of messages that each member sent, both to other members and to the group as a whole. In the study that relates to our topic of communication and group size, Bales and his coworkers computed the proportion of statements that each group member made. Measuring statements is not quite the same as measuring talk time because statements can differ in length. However, the concepts certainly relate. The researchers examined statements in groups ranging in size from three to eight people. We can compare the smallest and largest groups in order to illustrate the research findings.
On average, the members of three-person groups respectively communicated 42, 32, and 26 percent of the time. The most talkative member of eight-person groups made 38 percent of the total utterances. This was hardly a drop from the high of 42 percent in the three-person groups. However, the second and third most active people in the eight-member groups spoke during only 18 and 16 percent of discussion, respectively. In addition, the other five members only talked between 5 and 8 percent of the time each.
Therefore, as group size becomes larger, the one or two most talkative members still get the opportunity to speak as much as they wish. These members can remain satisfied. However, the majority of members in a large group do not get their desired opportunities to communicate. Their level of satisfaction can drop. In addition, when a group member has fewer opportunities to speak, he or she also seems to develop greater inhibitions in the group. The member is inhibited to speak even when the opportunity does arise. We have all probably felt such a process at work. Once we do not start something right at the first chance, such as talking freely in a group, it is often hard to begin at a future time. Thus, the majority of members in large groups can be both frustrated and inhibited. This combination can cause great dissatisfaction.
This large gap between talkative people and other group members also affects the group's perceived power structure. This, in turn, influences member satisfaction. We have seen how talkative people often are the most persuasive group members. They tend to be able to get the group to do what they want. In other words, these members assume power. As group size goes up, they assume more power relative to the less communicative members. Thus, larger groups have members who share power less equally than smaller ones. This can lead to a power hierarchy. In the hierarchy, a great majority of the members will have disproportionately less input into group operations. It follows that these members come to feel more and more powerless in the group. This can add further to their dissatisfaction.
Small Groups and Obligation
It appears so far that smaller groups should have more satisfied members than larger ones have. All members have more opportunities to talk in a small group, so they should be happier than if they were in a large group. However, a small group can have problems with feelings of obligation. When groups become too small, the opportunity to speak seems to turn into a felt obligation to keep communication going. Groups seem to wish to maintain a steady flow of interaction; this appears to be a general norm.
In larger groups, many people share the responsibility for sustaining interaction. One of these people is usually ready to speak at any time. However, in smaller groups, each member has a greater amount of personal responsibility for the flow of conversation. Members may even feel forced to speak at times when they do not wish to. This last possibility seems to threaten people. The result is that small groups of two or three people are not always conducive to member satisfaction.
The moral of the story is that intermediate-sized groups seem to lead to the most satisfaction. Slater (1958) asked groups of sizes 2 through 7 to work on "human relations," and then asked the members whether they thought their group was either too big or too small. More than 10 percent of members of two, three, and four-member groups thought their group too small, and more than 10 percent of members of six and seven-member groups thought their group too large. Nobody thought that groups of five members were either too large or oo small.
Success, Tasks, and Member Number
Other factors affect member satisfaction. We will discuss three of these.
Success. Group members tend to become more satisfied and cohesive if they perceive themselves as being successful over a long period of time. Even members who believe that they have little power or opportunity to influence the group may take pride in or identify with the group's success. They may be more attracted to the group because of the group's accomplishments.
Tasks. Task differences may have some effect upon satisfaction and cohesiveness. Certain projects are more pleasant than others. For instance, groups must work on coordination tasks together. Hence, the group's outcome depends upon its worst member's performance. This could leave the rest of the group disgruntled. In contrast, an accuracy task does not put such pressures on the group. We discussed the Frank and Anderson study (1971) earlier. This research also revealed information about maintenance variables. Members who performed coordination tasks regarded the project as less pleasant than people who worked on accuracy assignments. In addition, coordination task group members found their group less attractive. They also found their own work and their group's performance less satisfying. The researchers attributed this difference to the fact that coordination group members had to wait for everyone to finish an answer before any member could move on to different problems. This was not true for the accuracy project groups.
Member number. Member number can affect satisfaction levels. Groups with an even number of members are more likely to be dissatisfied than groups with an odd number of people. Even-numbered groups, unfortunately, can reach standoffs. This happens if an equal number of members favor two alternatives. The only way to resolve such a standoff is through conflict. Odd-numbered groups do not have this problem when they cannot reach consensus because they can at least reach a voting majority for one alternative. The vote will end the standoff. Reaching decisions through voting is not the best option that most small groups can use, but it does have the effect of ending disputes quickly and cleanly.
Coalitions and Satisfaction
Larger groups are more likely to form coalitions. These are subgroups that comprise a fraction of the group's members. A group may form coalitions in response to both maintenance and task pressures.
These subgroups can help member satisfaction, but they can have negative effects on the group as a whole. For example, two members may think that they do not have the opportunity to talk to the group as a whole. The two start to talk to each other as an alternative. This may increase their personal satisfaction. However, it is at the expense of group task functioning and cohesion. You have probably been in a group in which two friends continually whisper secrets to each other because they believe that the group is ignoring them. They seem content, but it is clear that their behavior harms the group as a whole. It makes their other friends uncomfortable and distracted.
Members might also create subgroups in order to resolve task pressures. They could form coalitions supporting particular group options or solutions. These coalitions can become very strong. Subgroup members may begin to identify with one another and with their chosen option more than they identify with the group as a whole. For example, a group of five businesspeople meet weekly to invest a pool of their money. One week they have an argument about the relative merits of stocks and bonds. Three people stand by bonds as the best investment option, while the other two believe in stocks. This task argument becomes so strong that it begins to color their weekly meetings. The three members become a subgroup of the "bond fanciers," and the other two call themselves "stock lovers." A feud develops, and the group has trouble discussing many things, not just the task options of stocks and bonds.
There are times when conflict is not bad. It is often helpful to group decision making. However, this is true only as long as the group eventually resolves the conflict or successfully manages it. For example, the investment group could begin to forget their differences. The end result might be that all the members see stocks and bonds in a new light, and the group gains knowledge. Or, the group could instead start to laugh about the subgroups and make the feud something almost "special" about the group.
A great deal of theoretical and research effort has gone into the question of coalitions. Researchers have examined when these subgroups form and which members create them. It appears people form coalitions when they can help increase each member's power. The members who form them are those who can benefit from the subgroups (see Chapter 5, "Power," for a discussion).
PUTTING THEORY INTO PRACTICE
Different Group Tasks
Thus far in this chapter we have discussed theory and research concerning group versus individual performance in four types of tasks. In the following paragraphs we will describe some of the implications of this work for decision-making groups.
Productivity Tasks
The implications of the previously discussed research on social loafing are clear. If your goal is productivity or speed, have group members work separately on a productivity task. If that is impossible, you must just accept losses in productivity due to coordination or motivation problems. However, you should try to take advantage of techniques that can decrease social loafing. You can lessen motivation problems by evaluating each person's work separately, for example. You could also give each person responsibility for a specific part of an assignment. Sanctioning a friendly competition among group members may also help. When you cannot take advantage of these techniques, your only option is to keep adding people until you have enough to do the task. You cannot help the fact that you are getting diminishing returns from each new addition.
But what if your goal was satisfaction rather than productivity or speed? Productivity tasks tend to be boring. Having people do it in groups rather than alone can make the tasks much more tolerable. Thus there may well be good reason to perform these projects in groups if you are willing to sacrifice some task performance for better group maintenance.
Coordination Tasks
The implications of this research are again clear. If your goal is speed, perform coordination tasks with the smallest group possible. Of course, with some coordination tasks, it is not possible to work with a small group. You may be in charge of an assembly line that requires eight workers, for example. You cannot use a smaller number of people. In such a case, you have the alternative of finding out which workers are incompetent and then either retraining or replacing them.
Single Stage Accuracy Tasks
The more people who work on an accuracy task, the more likely it is that one of them will be competent. This competent person will make it more likely that the group will discover the correct answer. However, it is likely that this improvement will be due just to having more people working on the task rather than to any improvement in communication among members. In fact, the research we discussed showed that interaction can actually negatively influence performance on these tasks. Interaction can hurt group accuracy when the most persuasive member is not the most competent. In addition, interaction will also slow down the group. Thus, if your main goal is accuracy, the best way to perform a single-stage accuracy project is to identify the most competent person and have them work alone if possible.
Multiple Stage Accuracy Tasks
It is to a group's advantage to turn any accuracy task into a multiple-stage task when it is possible. This is the best way to take advantage of the different abilities of group members. If it can, a group should divide an accuracy task into a number of parts. The group can then assign each section to suitably competent members, increasing the likelihood of an accurate answer.
Dividing an accuracy task into a number of parts also enhances the speed of the group. This is particularly true when the segments are independent--when the group members can complete them separately and then combine the results when each section is finished. If this is the case, the workers can complete all parts at the same time, as long as there are adequate skills for the tasks. This will increase speed.
If speed is not necessary, the group can gain the advantage of having two people work together on each segment or of having one person check the results of another. This will slow down the group's performance. However, it should enhance the final accuracy, as long as both people are competent.
However, we must emphasize again that these strategies will only work if the group has the proper organization. In order to adopt the correct organization, the members must know which members are competent at which part of the task and make sure that these and only these members work at that part.
Quality Tasks
We mentioned earlier that there are many factors that determine whether or not a group or an individual performs better at a quality task. Nonetheless, it has long been argued that quality tasks ought to be performed in groups.
In order to understand why this recommendation is so often made, it is helpful to compare quality tasks with accuracy tasks. As we know, accuracy tasks have objectively correct answers. For example, if a group is working on the mathematical problem of how much is two plus two, only one answer is correct. For this reason, it makes sense that some members' opinions regarding these tasks will be more nearly correct than other opinions in the group. Further, the group ought to follow the proposals of these competent members.
Quality tasks, however, are different. Quality tasks do not have objectively correct answers. Therefore, there is no way to be sure whether any group member can make a high-quality proposal. Instead, the goal of the group is to come up with a proposal that is most likely to be acceptable to the most people. Their best strategy is for the members to put their heads together and to try to reach a consensus that one option is better than all others.
This is a good time to define what we mean by a consensus. Surely when an important decision is being made it is rare that every member of a group is strongly supportive of the same option. More realistically, a consensus occurs when there is one option that every member of the group is willing to accept. Some members may not be very happy about that proposal and would prefer a different one, but each of them is willing to go along with the agreed-upon option.
As mentioned earlier, this is how the League of Women's Voters makes decisions. It is usually the best way to make decisions in quality tasks. Often, when a group cannot reach a consensus, it has to conduct a vote. The problem with voting is that there will be clear winners and clear losers. The losers may become unhappy and are less likely to be committed to the decision than the winners. When a group is able to reach a consensus, there are not as clear losers as when there is a voting minority. Thus there is likely to be greater willingness to support the chosen proposal.
It is clear that groups have the potential to come up with higher quality decisions than individuals. Further, larger groups have the potential to come up with better decisions than smaller ones. This is so for several reasons. Ideally:
1. A bigger group means that more relevant information is available to the group as a whole.
2. More people in the group bring greater diversity in viewpoints to the discussion. This means that a greater percentage of various interest groups will have input into a decision that affects them.
3. More people mean more minds to create the ideas.
4. In larger groups the odds are greater that group members will recognize a good idea and that someone other than the creator of the idea will remember it.
5. More people mean the odds are greater that the group will recognize a bad idea and correct it.
There are some drawbacks, however, to quality task groups. One is that the larger the group, the slower it will work. Trade-off between speed and the quality of decision-making is fundamental.
Another drawback is that the process of group decision-making can go wrong in many ways. When this happens, it leads to decisions that are likely to be worse than decisions that the group members could have made alone. For instance, a group can easily become embroiled in destructive forms of conflict. Under these circumstances, the goal of the group members becomes a desire to "win out" over the other members rather than to make the best decision. Another danger is that, as with other tasks, the people who talk the most in decision-making groups are likely to have the most influence, and the talkative people may not have the best proposals or be the most skilled at evaluating options. Further, these persuasive members may want the group to accept a proposal that is in their own best interest, not in the best interest of the group.
A final drawback is that, without good organization, a decision-making group can fail badly. The group must be properly organized. Otherwise, all the advantages that groups have in comparison with individuals, when making decisions, will not be realized. Organization becomes a problem as groups become larger.
For example, legislatures require a large size to ensure that they represent all interested groups. Legislatures handle the problems of organization through parliamentary procedures. These parliamentary rules work well, but they do so at the expense of the spontaneity of give and take. Smaller groups do not have this problem. They can use strategies that maintain a degree of organization while allowing some spontaneity. These strategies are different within small groups. Some give importance to organizational questions; others concentrate on allowing spontaneity. We will describe some of these small-group procedures in Chapter 13, "Formal Procedures for Group Decision-Making."
When these drawbacks are successfully addressed, decision-making groups can utilize all their advantages, as we have listed them above.
Another good reason that groups can make better decisions than individuals concerns how a decision is accepted. For a decision to be successful, it must be acceptable to the greatest number possible of the people it will affect. People have different interests. A group must take these interests into account when it makes a decision.
When a decision occurs, one can usually consider the people it affects as members of interest groups. For example, when the administration of a university has to make an important decision, its leadership needs to consider several interest groups. These include, at least, graduate and undergraduate students, the students' parents, faculty, staff, government (local, state, and federal), local and state business interests, and the surrounding community. All these groups have different desires, and a successful decision requires a compromise. The best way to get the decision-making body to consider all the special interests is to have its membership include a representative from each group. Further, members of special interest groups are more likely to accept decisions if their representatives have been included in the decision-making process.
A final advantage of groups over individuals in making decisions is that the experience of making a group decision appears to lead to a commitment among group members to the decision that does not occur in individual decisions. Several studies have supported this idea. For example, during World War II the U. S. government asked housewives to serve some of the less desirable meats to their families as part of the war effort. Kurt Lewin (1943) found that women who discussed and decided as a group to use these meats were more likely to actually do so than women who heard persuasive talks about the value of these meats and said that they were persuaded.
Ideal Group Size
The ideal size for a group depends on its goals. As we have seen, the goals, in turn, depend on the group's task. Whatever the task and goal, each group must make trade-offs. The goal will determine which side of the trade-off to emphasize.
For example, there is a trade-off between speed and quality in decision-making groups. As group size increases, quality increases at the expense of speed. If quality is the foremost goal, one may want a group of seven or more people. In contrast, if speed is most important, the group should have four or fewer members.
Group Number
However, there is another aspect to group size that we should consider. Group number affects goals in different ways. Decision-making groups with an odd number of members can resolve impasses quickly by vote. This is not true for organizations with an even number of people. They must debate standoffs before they can solve them. A great deal of debating can slow a group down. It can also lower cohesiveness and group satisfaction. However, debates also can increase a group's decision quality.
We should consider these factors also when planning the ideal group size. Group member number is important. For instance, odd-numbered groups of seven or nine people may not be best for the goal of quality, even though they are large, because they can vote their conflicts away. Four-person decision-making groups may not be suitable for speed, though small, because they may reach a two-against-two deadlock.
Task and Maintenance Factors
With other types of tasks, there is a trade-off between task and maintenance output goals. For example, in productivity tasks a group may have to exchange some performance for satisfaction. We have seen how task output per person decreases when group size increases. For instance, five typists working together produce less than the same five working separately. Individuals should work alone if speed or productivity is essential. However, people generally enjoy working on productivity tasks in groups. This is because these jobs are usually boring. The human factor may often outweigh the task side of the project.
The Number "Five"
There are some good arguments for a group size of five for quality tasks. This can serve as a compromise when a group values speed and quality equally. Five generally allows for adequate diversity among member viewpoints. Yet, it is still a relatively small group, allowing for quality without sacrificing too much speed. It is also the ideal number for satisfaction because it is neither too large to restrict member opportunity to talk nor so small that people feel obligated to speak. In addition, the odd number can help the group members resolve conflicts.
Evaluating Group Size
However, once again, everything depends on the goal to be achieved from group interaction. It is important to understand all of the factors involved in the functioning of groups: how different tasks affect group process, how different sizes and different types of desirable outputs can alter a group's functioning. Sometimes, the best decision may be not to use a group.
Table 2.5 summarizes the effect of group size on the output variables of quality/ accuracy, speed, and member satisfaction. An overall level is included for each output variable for groups containing from three to eight members. The overall level for each group size is relative to the other group sizes. For example, saying that overall speed is "very high" for groups with three members means that speed should be higher in three-member groups than in other-sized groups. The overall level is based on the sheer number of members and whether that number is odd or even. Of these, sheer number is more important and therefore weighs more heavily in determining the overall level.
Table 2.5 Summary of group size effects on output
Group Size
Output Variable Factor 3 4 5 6 7 8
Quality Number Hurts Hurts - - Helps Helps
and Odd/even Hurts Helps Hurts Helps Hurts Helps
Accuracy Overall Very low Low Below average Above average High Very high
Speed Number Helps Helps - - Hurts Hurts
Odd/even Helps Hurts Helps Hurts Helps Hurts
Overall Very high High Above average Below average Low Very low
Satisfaction Number Hurts Helps Helps Helps Hurts Hurts
Odd/even Helps Hurts Helps Hurts Helps Hurts
Overall Low Average High Average Low Very low
SUMMARY
Scientists have performed many experiments to compare the performances of groups and individuals. These studies date from the beginning of experimental research in the social sciences. Early studies supported the theory of wholism. which maintains that interaction among group members allows each member to work better than he or she could alone. However, these studies were flawed.
Later research supported the theoretical assumption of reductionism. This hypothesis holds that interaction at best limits each group member to performance levels that are equal to what he or she could have attained working alone. However, group interaction generally results in each member performing worse in groups than when alone. The idea of reductionism forces us to consider whether people should ever work together in groups.
Practically speaking, the reductionist point of view is probably accurate for some tasks. There are four basic types of tasks that follow the reductionist idea.
The first category involves the productivity type of project. Productivity tasks have an outcome that is the combined total of the work of each group member. For example, a group of four typists will have a total productivity of 400 addressed envelopes if each types 100 addresses. Productivity per person decreases when people work on productivity tasks together. Thus, a group of four typists working together would finish fewer envelopes than the four working alone would have. Groups do not perform these tasks better than aggregates of the same size.
The second category is coordination tasks. These assignments require the coordinated effort of a certain number of people. Large numbers of people make it more likely that a group will have coordination problems. Therefore, people should perform coordination projects with as few people as possible. The third category--accuracy tasks--also supports the reductionist perspective. They involve tasks that have objectively correct answers. Accuracy projects need competent group members to solve the problem. The group should identify the group member who is most likely to come up with the answer. That person should work alone. Group interaction could confuse and slow down the capable person, as well as causing other difficulties.
Other tasks, on the contrary, support the idea of wholism. One example is accuracy tasks with multiple parts. Groups may contain members who are competent at different parts. In this way, groups can perform multiple-stage assignments better than individuals. However, this is true only if the groups can coordinate their efforts efficiently. Finally, quality tasks have no objectively correct answer. It is best to solve such a problem in groups. Groups allow as many of the concerned parties as possible to influence the decision.
The ideal size for a group depends on the group's goals. There are some inevitable trade-offs that groups must make. Different output variables need different group sizes. The dream of one ideal size is impossible to attain. Larger groups generally make higher quality decisions than smaller ones. However, they take more time to reach their conclusions than a smaller group would.
The other categories of possible tasks are different. Productivity and accuracy generally are improved if people work alone on these other projects. Yet, satisfaction is increased if people can work in groups. This is particularly true if the job is a boring one. It is clear that a person organizing a group must keep many things in mind before deciding on the best group size.
It is difficult to create general rules for the ideal group size. A person
should instead understand the manner in which different group variables
relate to one another. This will lead to better decisions concerning group
size than any rules of thumb could provide.