|
This is an online version of a paper delivered at the Joint ACH-ALLC Conference, University of Virginia, 9-12 June 1999. |
Encoding a Transcript of the Beowulf Manuscript in SGMLElizabeth SolopovaThe design of Standard Generalized Markup Language (SGML) encoding for the Electronic Beowulf was determined by the aims of the project and its material. At the center of the project is a single manuscript, highly problematic because of its present damaged state and a complicated early history. The manuscript is the work of two and possibly more scribal hands and shows signs of extensive early editorial activity. Many features of the Beowulf text and the manuscript suggest the poem's short history as a written text; in other words the poem appears to have acquired its present shape close to the production of its only surviving manuscript.1 The electronic edition provides various tools for re-evaluation of manuscript evidence for the poem: these include the SGML search engine which allows advanced searching of the transcript of the manuscript and the edition of the poem produced for Electronic Beowulf. The SGML encoding of the edition and the transcript is aimed at making searchable features important for the study of the poem's early history and the history of the manuscript. Some of these features are themselves problematic and allow for more than one interpretation. All this called for an approach different from the one taken by the Canterbury Tales Project, for example.2 Both the Canterbury Tales Project and the Electronic Beowulf use sophisticated SGML encoding. The emphasis in the Canterbury Tales Project, however, is on structural encoding which allowed various types of comparison of multiple witnesses, including collation and creation of linguistic databases. Textual and linguistic comparison of witnesses made possible by the Canterbury Tales Project CD-ROMs required giving unique ID's to every line in every witness, and lemmatization of every word in every witness with the record of grammatical information about the word and regularization of its spelling. The description of features relating to the physical appearance of the text in the manuscripts and to some extent to the scribal activity is done in a more conventional way through witness descriptions, transcription introductions and textual notes. It was impossible within the scope of this project to identify scribal hands and classify paleographical features across over eighty fifteenth-century witnesses with the degree of consistency and systematic completeness necessary for SGML encoding and searchability. Only scribal deletions and additions in the manuscripts are searchable via the search forms in DynaText on the Canterbury Tales Project CD-ROMs.3 Some other features such as 'damaged', 'emphatic script, 'ornamental capitals', 'underlined', 'unreadable', 'dubious' and 'blank space left by the scribe' have been encoded and can by searched by typing SGML tags in the DynaText search field. Structural encoding in Beowulf includes marking the division of the poem and the manuscript into fitts, folios and lines and marking the borderline between the work of the two main scribes. This allows the user to limit searching to various parts of the text, for example to search for abbreviations used by the first scribe only. Apart from this the transcript has extensive encoding of scribal and paleographical features and the edition includes encoding of emendations and restorations by editors and early transcribers of the manuscript. Encoding relating to scribal activity and the physical state of the manuscript includes markup for abbreviations, accented letters, scribal additions, deletions and alterations, of written over erasure, treated with reagent, faded, damaged and missing text with its early restorations, uncertain readings, as well as letters covered and partly covered with restoration materials. For most elements additional information is recorded through the use of attributes, for example alternative interpretations for uncertain readings; responsibility, place and method for scribal corrections; the use of ultraviolet photography and digital image processing for determining various difficult readings. The additional information associated with each element and recorded through attributes is of particular importance for the interpretation of the feature. Thus with scribal additions we wanted to record the scribe responsible for the addition, its place -- for the manuscript has interlinear additions, and additions made by squeezing new letters between those originally written -- and finally the use of an insertion mark. In most cases the scribes use either a point or a stroke to indicate the intended place of an addition. The stroke is particularly associated with the second scribe. Thus a typical encoding for a scribal addition is as follows: scyppen<add resp=scribe2 place="&intrl;" rend=stroke>d</add>.4 Abbreviations were expanded and encoded with a record, within the attribute 'TYPE', of the character used by the scribe: <abb type="ampersand">7</abb> This is an example of SGML encoding for lines 7-9 on folio 179r, arguably the most difficult folio in the whole manuscript:  <folio id="179r" linerange="(ll. 2210a-2231a)" name="f. 179r"> The folio is partly unreadable, and is a palimpsest with secondary erasures, overwriting and an offset from the facing folio.5 The ultraviolet image shows that it was probably treated with reagent as a part of a restoration effort at the British Library in order to make the faded text better visible.6 The example shows encoding of such features as the use of reagent (<RGT>), palimpsest (<PLSTUPPER>, <PLSTLOWER>), damage (<DMG>), uncertain readings (<UNCN>), restorations (<RES>), faded text (<FDD>), text written over erasure (<OVERERS>), readings enhanced with ultraviolet photography or digital image processing (<ENH>) and so on. This encoding is a first stage of the project and can be extended by the record of other features, such as text resulting from the offset from the facing folio. The markup used for Electronic Beowulf is not TEI-conformant but is indebted to TEI for both ideas and individual decisions. We did not use the TEI tag set for the encoding of primary documents because in our experience it is not detailed or elaborate enough to make encoding at the level required for the project successful. It was sufficient for the record of palaeographical detail performed by the Canterbury Tales Project, but requires further elaboration and testing for the more detailed paleographical analysis which was necessary for Beowulf. It may be possible to record all this information using the TEI tag set, but it would have resulted in overcomplicated encoding confusing for both the human reader, and for the software -- a practical consideration which has to be taken into account in any real-life situation.7 SGML encoding is made accessible to the user of Electronic Beowulf through the search engine interface: the results of searches on SGML elements can be viewed by selecting the 'Show SGML tag' mode which shows the encoding used for the displayed element: 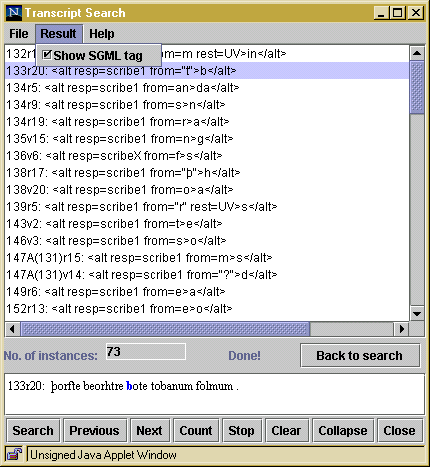 We believe that encoding is something the users may wish to see: the understanding of how results are generated will make misinterpretations of these results less likely. We also anticipate that eventually the users will be able to construct their own searches using SGML in the same way that it is possible in DynaText. This will require the interpretation of encoding by the interested users and makes simplicity and lucidity highly desirable qualities for the markup. The greatest difficulty in designing SGML encoding for Beowulf was the purely intellectual difficulty of classifying and representing as a system a complex and often idiosyncratic material evading a single interpretation. This difficulty is common for descriptive textual encoding in general and for descriptive encoding of primary documents in particular. Our aim was to create a systematic classification of textual elements which would not be foreign to the text, would not obscure its properties to the reader through either over- or under-interpreting, would be capable of both raising and answering questions and of highlighting the problems rather then glossing them over. Our hope is that such a system would not stand in the way of further research by providing ready-made answers acceptable for some but not for others, but would assist in extending research in directions not necessarily predictable at the moment of publication of the CD-ROM. Encoding is interpretative by definition, but in a research tool such as the Electronic Beowulf it has to be flexible and achieve a useful compromise between providing answers and asking questions. We also encountered some special encoding problems. The first group is represented by cases where the element which needed encoding was smaller than the smallest segment of the electronic text -- the character. An example of this is a situation where only a minim of a letter was erased or deleted by the scribe through underdotting or on the contrary, added by the scribe in order to correct some error. A correction of this kind occurs in line 5 on folio 146v where a minim was erased by the scribe after the word '�thran':  A similar problem occurs with partly damaged or partly covered letters on the burned edges of the folios. The editor's comments referring to damaged letters range from 'now only the descender survives', to 'part of the letter survives', to 'only traces are preserved'. Depending on an individual reading and on the degree of damage, the editorial restoration of these partly surviving or partly covered letters may be more or less problematic. In every case it was important to indicate that the evidence for a particular reading is incomplete and may come from other sources than the manuscript in its present state. It was desirable to record an approximate degree of damage in order to show how complete and reliable the evidence is: for a textual critic there is a big difference between 'missing' and 'partly surviving', even when surviving traces of ink are not themselves sufficient for a reconstruction. The situation where the feature under consideration is smaller than a character is of course not just a problem of markup, but more generally the problem relating to the transcription of handwritten text into computer-readable form. It covers not only characters incomplete in the original document, but also characters which can not be interpreted with complete certainty. Graphic distinctions used in a modern character set may be considerably different from the corresponding distinctions in the handwritten text. Thus although fifteenth-century English scribes used the same repertoire of minim letters as is used today (u, n and m) the letters were often distinguished only by the number of strokes and not by joining the tops or the bottoms of strokes. Series of minims which can be interpreted in more than one way are not uncommon in Anglo-Saxon and Middle English manuscripts and may make us wish to have for their representation a character smaller than 'n', 'm' or 'u', such as a 'minim'. An example of this in Beowulf are the letters 'bet' in line 6 on folio 198v followed by two minims joined at bottom with a stroke through the second minim:  The situation is highly idiosyncratic and uncertain and is therefore difficult both to transcribe and to encode. TEI offers a method for treatment of features smaller than a character for some of the elements of its primary documents tag set. The element 'damage' (<DAMAGE>), for example, has an attribute 'EXTENT' which, according to the TEI Guidelines, can have such values as 'half-letter', 'minim', etc. However this attribute is not available for other elements such as 'deletion' (<DEL>), for example. In Electronic Beowulf both descriptive notes and special markup were used in such cases. We distinguished between 'covered' (<CVD>) and 'partly covered' (<PCVD>) letters. Letters encoded 'restoration' (<RES>) are usually those lost in the manuscript, and supplied from other sources, such as the Thorkelin transcripts of Beowulf. However when a letter was partly preserved, usually in a very fragmentary state which required the use of external evidence (from the Thorkelin transcripts) for its editorial restoration, it was encoded both 'restoration' and 'damaged' to alert the readers to the fact that some evidence for the reading is still preserved in the manuscript itself. Such letters appear in the transcript in brackets which indicate fragmentary preservation and dependence of the reading on either Thorkelin A or B: �rym ge frunon hu�a ��elingas elle(n) Description of the partly surviving element was also used in some cases. Thus the deletion in line 5 on 146v described above was encoded as follows: <del resp="scribe1?" value=minim rend=erased rest=UV>[:]</del> and the possible abbreviation in line 6 on 198v as follows: bet<uncn>[<i>i<abb type="crossed minim (m?)">m</abb></i>]</uncn> Another set of encoding problems is represented by multiple scribal corrections and alterations which were carried out in a particular order. This can be illustrated by an editorial note which accompanies the reading in line 11 on folio 169v: 'after ��eling two or three letters erased; traces indicate a series of mistakes and corrections (um with m underdotted, u with macron above, and perhaps e, all eventually erased).' 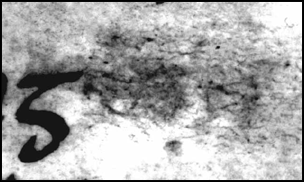
All types of scribal activity mentioned in the note, such as additions and deletions by various methods, are commonly encountered in the manuscript and were encoded through a corresponding set of elements and attributes. Cases of multiple subsequent scribal corrections, however, not only defy conventions which work well for the large majority of simpler cases (for example recording added text within an element and deleted text within an attribute), but present particular difficulty because of the need to record the order in which they took place. Situations of multiple scribal activity were dealt with on an individual basis through the use of special markup and descriptive notes. In most cases it did not make sense to encode each correction separately, as a series of deletions and additions: this would have obscured the fact that they are interconnected and would have confused the situation rather than clarified it. Encoding corrections as a 'cluster' and numbering their order was also not practical, because such cases are few, each has unique features and the order of the corrections is not always clear. All this prompted a wide use of descriptive notes. The correction on folio 169v described above was encoded as a deletion with the whole process of scribal changes recorded under the attribute 'VALUE':
Yet another group of difficult cases were those where some ambiguity was present in the material itself and the encoding had to reflect that the interpretation is tentative. An example of this is described in the following editorial note for line 21 on folio 179v: 'After dream, traces of erased or faded letters, sometimes restored as ic, appear to be bottoms of h and e under ultraviolet light'. The tag 'uncertain' (<UNCN>) and a question mark following the reading recorded as a value of the attribute 'alternative' (ALN) were used to express uncertainty:
A similar difficulty occurs when a particular feature falls under two or more categories distinguished within the system of markup. Thus a common method of deletion in Anglo-Saxon manuscripts is underdotting a letter or a word. On the other hand a point or a stroke beneath the line is commonly used by the scribes to indicate the place where additions written above the line were meant to belong. There are cases however, where it is impossible to say whether a point (or a stroke) beneath the line is an insertion or a deletion mark, for in fact it stands for both. An example of this is the word 'fah' corrected from 'fac' in line 9 on folio 179r. 
The stroke below 'c' can be interpreted both as a mark of cancellation and as caret sign indicating the position of 'h'. In such cases the fact that an addition and a deletion are interconnected, and that the stroke has two functions was rendered through cross-referencing: <overers resp=scribeX ersdtext=unreadable>fa<enh src=UV><del resp=scribeX value=c rend="stroke beneath c (also insertion mark for h added above)" rest=UV>[:]</del><add resp=scribeX place="&intrl; above c" rend="stroke beneath c (also deletes c replaced with h)">h</add></enh></overers> Cross-referencing and recording of additional information in the markup was broadly used to represent complex evidence for individual readings in Beowulf. Thus apart from recording the fact that a particular word is missing from the manuscript and in the edition is a result of an editorial restoration based on the Thorkelin transcripts, it was also important to record the information concerning the status of the reading in the transcripts themselves. Some readings appear to be later additions in the Thorkelin transcripts and therefore may have already been lost at the time the transcripts were made. This casts doubt on the usually reliable source of evidence and suggests that some readings in the Thorkelin transcripts were editorial conjectures rather than reproductions of the text in the manuscript.8 This descriptive additional material had to be integrated into the markup and into the display of the search results on the CD-ROM. A typical encoding of a restoration based on the Thorkelin transcripts is then as follows:
The results of the search for restorations based on Thorkelin A are presented in the transcript search interface in the following way: 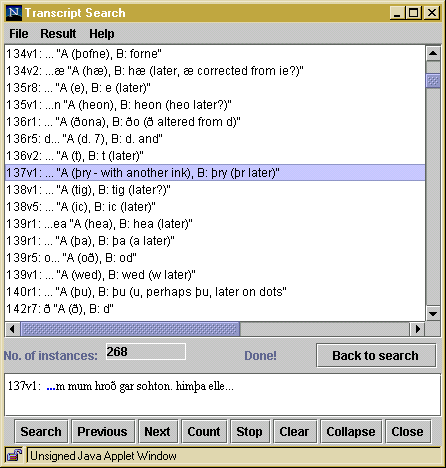 In general terms the SGML encoding in the Electronic Beowulf was very much an attempt to work a complex and diverse editorial textual and paleographical commentary into the text through the markup. We wanted textual features to be retrievable not in isolation from, but together with commentary questioning or supporting our interpretations. We aimed to make features relating to the physical appearance of the manuscript searchable as an aid for the interpretation of the digital facsimile. In spite of the technical and intellectual difficulties encountered on the way, we believe that the quest for SGML for Beowulf has been successful: we have achieved results desirable for this stage of the project without making too many compromises or sacrificing any of the project's academic goals. |
Notes1. Kevin S. Kiernan, Beowulf and the Beowulf Manuscript, 2nd edition (Ann Arbor: University of Michigan Press, 1996). 2. Peter M. W. Robinson, ed., The Wife of Bath's Prologue on CD-ROM (Cambridge: Cambridge University Press, 1996); Elizabeth Solopova, ed., The General Prologue to the Canterbury Tales on CD-ROM (Cambridge: Cambridge University Press, forthcoming). 3. DynaText software used for the Canterbury Tales Project publications was created by Electronic Book Technologies, Providence, Rhode Island. 4. The attributes used are 'RESP" to record 'responsibility' or the scribe responsible for the addition, and 'REND' to record 'rendition', in this case the use of the insertion mark. 5. Kiernan, Beowulf, 219-43. For the offset image from 178v, see the editor's notes for 179r and subsequent references to editorial notes in Kevin Kiernan, ed., The Electronic Beowulf, CD-ROM (London: British Library Publications and Ann Arbor: University of Michigan Press, 1999). See also the interactive image that opens from the top toolbar on 179r. 6. See Kiernan's notes for this folio and subsequent references to editorial notes in The Electronic Beowulf. 7. The code for indexing and retrieval of SGML elements was created specially for the Electronic Beowulf by Cheng Jiun Yuan at the University of Kentucky. 8. Kevin S. Kiernan, The Thorkelin Transcripts of Beowulf (Copenhagen: Rosenkilde and Bagger, 1986). |