
Images: Quantity is not always Quality
Michael Lesk
Bellcore
Abstract:
People like looking at pictures. Scanning is cheaper than keyboarding.
These two facts have encouraged many to design scanning projects, as a
way of converting information to machine-readable form for access
and preservation. This does not mean that everything should be
scanned: images are also bulkier than text and less easily processed.
This paper will address practical issues in scanning and manipulating
images, addressing the fact that technology in some areas has outrun
our knowledge of how to use it.
Just because your scanner has a 2400 bpi choice in its menu, that does not
mean it should be invoked, for example.
Our experience on the CORE project suggests that people can read images
as rapidly as other forms of scientific articles, and that 300 dpi is
good enough. The main questions in image systems are bandwidth,
screen display, and cataloging. The most important possible tradeoff
is whether fast enough display will compensate for our inability to
search images effectively.
1. Introduction.
The use of images in computer systems is often attractive. There is no longer a need to worry about screen display style, the user gets something that looks just like what they are used to, and the systems rarely cares what it is that is being displayed. Much less programming is needed for the same amount of material in a retrieval system. Images can display information that is lost in the process of transcription; Figure 1, for example, shows a page from the notebooks of Charles Sanders Peirce, in both transcribed and scanned format.
Images can also help when the transcription process is uncertain: Figure 2, for example, shows a bit of the Daily Journal (London) for March 7, 1728, scanned from microfilm.

There are characters that are hard to read but can be guessed from context, and the individual reader may prefer knowing what was clear and what is being guessed, rather than relying on the editor.
Images do limit what can be done with the digitized material. Searching is harder, and will depend on other catalog information. Images are hard to reformat to fit other window sizes, nor can people with limited eyesight ask for larger characters. The size (in bytes) of digitized images pushes towards CD-ROM distribution instead of online (which also means that images are harder to steal). Image systems are therefore harder to employ in a networked world, since they take so long to transmit.
Many kinds of materials can be imaged, ranging from ordinary printed pages to works of art to maps to objects. Every imaging project should understand questions such as:
1. Are these images substitutes for the originals, or merely ways of finding them? Art historians often say that their detailed work can never be done except with the original object, but images, photographs, and the like are useful to select what to study. For ordinary printed pages of text, it is likely that the image can satisfy the needs of the ordinary user (after all, microfilm has been doing this for decades).
2. Is the importance of the original its abstracted content (the string of words in a text, or the space represented by a map) or are the details of format important? How much of the format was controlled by the original author or artist: it is not likely to be worth a lot of effort to preserve the page layout chosen by some modern compositor, while a poet's page arrangement is often of value to a critical reader.
3. Is the object important as an artifact? Or can it be destroyed in the process of scanning? How durable is it, and how many other copies exist? Right now scanning of paper which is strong enough to be sheetfed is much faster than scanning material which must be handled carefully. In fact, the easiest thing to do with a fragile book which can not be destroyed is going to be to photocopy or photograph it first, since these technologies have been around longer and are more developed in their ability to copy fragile objects; the copy can then be scanned.
4. What kind of cataloging exists? What kind of cataloging is needed? Is the item self-describing (e.g. a scanned book including the title page) or is it something, such as a landscape or portrait, in which auxiliary information is vital to help the user make sense of the item? How can the funding for cataloging, which may well be more expensive than scanning, be obtained?
The most typical project involving scanning is straightforward scanning of printed journals or books to replace the traditional paper copy. Such a scanning project can be done in a relatively straightforward way and rapidly; it can provide decent service to users; and it does not involve difficult questions of preservation of the original object, which is likely to be of little value. Scanning can either involve modern printing, as in the Adonis,[1] Tulip,[2] RightPages[3] or CORE[4] projects, with the goal of providing faster or more convenient access; or it can involve older material, such as the CLASS[5] or Open Book[6] projects. Scanning of old material is normally only for reading; it is an alternative to keyboarding, but much cheaper (keyboarding a typical page might cost about $2.50, while scanning it is likely to be 10 cents). More complex projects can involve manuscripts, such as those involving Canterbury Tales or Beowulf, or photographs, maps, paintings, and other objects.
This paper will not cover much about color scanning, which is admirably described in a recent book by Peter Robinson,[7] nor optical character recognition, which is now a thriving commercial business, even though imperfect.
2. Scanning recommendations
Most scanned material is divided quickly into printed pages, monochrome, which is usually scanned one-bit-per-pixel and compressed with lossless compression algorithms; and color material, scanned at 24 bits per pixel and compressed with lossy compression algorithms. Printed pages can be scanned rapidly; sheet-fed machines with speeds of 20 to 40 pages per minute are easy to buy. Color pages are slow to scan, and may take up to twenty minutes or so. They are typically scanned on flatbed hand-placed scanners.
Resolution seems to be the main question people ask. The first basic fact about resolution is that today CCD cameras can only be built to a resolution of perhaps 600 dpi. Anything advertised above this resolution is interpolating between the actual samples. Note that very high quality photographic technology can far exceed this resolution (1000 lines/mm is possible, albeit on glass plates) but your eye can't see that well. If the intention is to capture information that a person can read on the original page without a magnifying glass, about 200 dpi is adequate.
To understand why 200 dpi is enough, consider the problem of reading 6 point type. A typical letter in such type is about 3 points wide, or 1/24th of an inch. Although one can make a readable alphabet with a 5x7 dot matrix, that requires the letters to be aligned with the dots. Allowing 8 dots wide instead of 5 to deal with the misalignment of the letters and the scanning grid, this implies that about 200 dots per inch are required for the digitization.
Higher resolution scanning is now being demanded more and more. Part of this is that scanning devices which will do 300 and 400 dpi are now common. Part of this is that for small type, the difference between 200 and 300 dpi scanning is perceptible. In the CORE project we started with 200 dpi, and then had people at Cornell complain that they wanted higher resolution (mostly to deal with small labels in figures). Above 300 dpi, people can no longer see the difference without optical assistance (see Robinson's book). However, there is much interest in 600 dpi scanning, or even higher levels, based on the availability of the scanning devices. Some preservation experts are worried about 3 or 4 point letters and figures, appearing in equations or as superscripts in tables. Others are trying to capture as much information as possible to allow corrections later for staining, yellowing, or other deterioration of the original. At times one gets the argument that ``if we don't do this job as well as we can, somebody will have to come back and do it again later'' which can be used to justify almost anything (the other side is Voltaire's aphorism ``the best is the enemy of the good''). In reality, 300 dpi bitonal scanning of ordinary printed material is probably enough for practical purposes.
Although text printing is entirely bitonal (one bit per pixel), grey-level information, at least for a few levels, helps in readability. Figure 3 shows a sample of a table from a chemical journal which was scanned originally at 300 dpi bitonal, and which is presented at one-third resolution in bitonal (1 bit per pixel), and with 2, 4 and 8 bits of grey information.
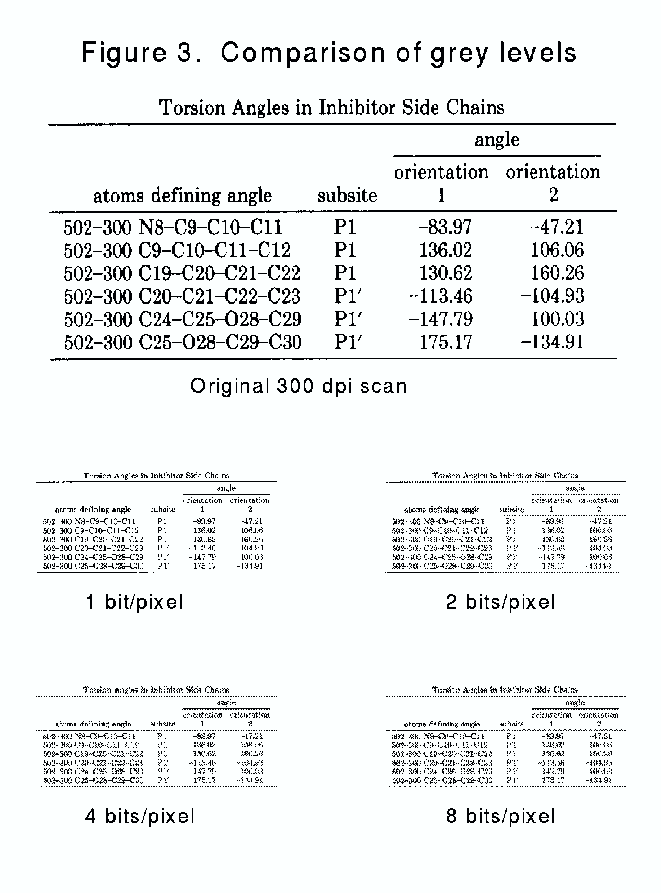
As can be seen, there is a substantial improvement in readability from 1 bit to 2 bits; there is less improvement going to four and 8 bits. There is also a substantial storage cost: the 1/3 representation with 8 bits/pixel takes more space than the original, higher-resolution image. For example, here are the sizes of the images shown in Figure 3:
Table size, in bytes
---Image------Bytes(raw)-----Bytes(compressed)
300dpi, bitonal-----60044----------6368 (G IV fax)
100dpi, bitonal-----6713-----------2595 (GIF)
100dpi, 2bits/pixel---13418----------3675 (GIF)
100dpi, 4bits/pixel---26828----------5048 (GIF)
100dpi, 8bits/pixel---53648----------6868 (GIF)
GIF compression works better on these images than JPEG, since they are the ``small number of colors'' examples where GIF is most effective. Thus, on balance, for the most efficient combination of readability and storage use, a small number of bits per pixel should be employed. Now the bad news: you'll have to write your own code, since nearly every piece of software that handles grey scale uses one byte per pixel, no matter how many levels you might actually be using. You can use GIF for storage, but you'll find it being converted back to 8-bits/pixel for display.
Actual scanning devices (and actual printing devices) often attempt to deal automatically with grey scale, either by (a) automatically dithering to imitate grey scale with black and white bits, or (b) automatically interpolating to produce grey scale from something that was only black and white. Thus, the user may well find that something that should improve readability has no effect, because some piece of software in the device is making unrequested but unstoppable changes. For example, the CLASS project used a scanner which actually scanned 400 dpi, 8 bits per pixel. This was converted to 600 dpi bitonal. The most readable and most efficient format might have been 400 dpi with 2 bits per pixel, but (a) there was no way to stop the scanning device from doing its conversion, and (b) I doubt the staff would have been willing to discard the extra grey bits, thus making the image much bulkier.
Although informal scanning and printing often benefit from interpolating or dithering, for a carefully done project such image enhancement should not be done on scanning if possible. The scanner should do what it is physically capable of doing, and material should be scanned bitonal if it was originally printing or line-art. If it turns out that dithering or smoothing will improve readability, that can always be done later with appropriate software. It can be very frustrating to be unable to bypass some feature on a scanner or printer.
There are a wide variety of scanning machines made. The low-end scanning machines are flatbed, with no feeder, and requiring several minutes per page. Typically they will do color scanning as well as black and white, and can cost as low as $1000 (although prices such as $3000 are more typical). Medium-price devices cost about $20,000 and provide scanning of both sides of a sheet (duplex), stack feeders, speeds of 20-40 pages per minute, but only black and white scanning. Higher priced machines, of up to $250,000, can scan up to 200 pages per minute and have more advanced paper transport mechanisms. On balance the best strategy is to use a machine adapted to your project budget (but have your own, since contracting out at present is quite expensive), and scan bitonal at 300 dpi, creating grey-scale on reduction to lower resolution for display.
3. Formatting
There are several well-known standards for storing images, chosen for reducing the size of the images. TIFF, the Tagged Image File Format, is mostly a wrapping format; it can support several different kinds of compressed representation internally. For page images, the normal compression method today is Group IV fax, defined by the international standards organizations. It involves run-length encoding plus line-to-line encoding; an ordinary page, 1 Mbyte uncompressed, reduces to 30 Kbytes or so in Group IV compression. A very dense page (such as a page of an ACS chemical primary journal) takes about 100 Kbytes in Group IV.
Fax compression is so-called ``lossless;'' the original image can be reconstructed exactly. In this way it is similar to the Unix ``compress'' program, or to PKZIP, or many other kinds of data compression. Unlike these more general lossless compression algorithms, it is tuned for images of printed pages, and it is particularly good at this kind of data. For example, a very dense printed journal page, 1 Mbyte in uncompressed form, took 146Kbytes in Group IV and 273 Kbytes with ``compress.''
Screen sizes, today, are much smaller than scanned image sizes. A 300 dpi image of an 8.5x11 page needs a screen 2400 dots wide and 3300 dots high. Today there are few screens larger than 1600x1280 and the most common sizes are either 1152x900 (Sun workstations) or smaller (1024x780 is common on large-screen PCs). In fact, for the CORE project we found, particularly for figures, a need to go to 150 dpi as the standard storage form; otherwise the part of the picture that was visible was just too small and required too much panning around.
Michael Ester has done a study of the effects of resolution on viewing.[8] He found that as quality increased, there was a noticeable break at 1000x1000 resolution and 8 bits of color per pixel. Improving resolution or color representation beyond this point (for viewing an art image) does not produce further rapid improvement in perceived quality.
Compression is even more important for color images, which can be extremely bulky. The Library of Congress, for example, has a map scanner which is flatbed, 24x36 inches, 600 dpi, 24 bits per pixel. Multiplying that out, a single scan is 900 Mbytes. Thus, there has been great stress on color image compression.
To understand color compression, it is important to realize that although the scanning process usually recovers 3 bytes per pixel, allowing 8 bits each for the red, green and blue components of the reflected light from the picture, most displays can not deal with the complete gamut of colors. Instead, most computer screens maintain a colormap, in which one of 256 possible color names are mapped to the full color space. Thus, part of compressing the image is to reduce the colors to a limited set of hues.
The three best known formats are JPEG, GIF, and Photo-CD. To summarize very briefly, JPEG (the name stands for Joint Photographic Experts Group), is a publicly available and efficient compression algorithm. It is based on a block-by-block spatial Fourier decomposition of the image, and is designed to do a good job on ordinary photographs of natural scenes. JPEG provides a high degree of compression, but takes quite a while to compute.
GIF is an algorithm believed for many years to be publicly available, but apparently using a compression algorithm patented by Unisys. This is part of a much larger dispute over the ownership of the Lempel-Ziv algorithm and related compression methods. Unisys has made clear that only for commercial exploitation of the algorithm will they seek licensing revenues. GIF is based on run-length compression of a small color set. Thus, it is particularly effective at compressing images which contain only a few discrete colors. This means that GIF is much better at compressing a computer generated image than a scanned image, which is much less likely to have a limited color palette. For most scanned pictures, JPEG will be preferable.
Kodak's PhotoCD is another very common representation. The PhotoCD storage method (``ImagePac'') is proprietary to Kodak; no one else is allowed to generate pictures in this format. The PhotoCD storage mechanism does not try to compress as much as JPEG; this means it is faster to access PhotoCD images, and that they distort the original less than JPEG images. The PhotoCD system keeps luminance at double the resolution of chrominance, meaning that contrast detail is better than color detail. For most normal pictures this is a sensible choice. PhotoCD is a very standard process; the maximum resolution is 2048x3072 for the normal PhotoCD, and double that (4096x6144) for the ``Professional PhotoCD.''
In any kind of scanning, it is important to realize the limitations of the various devices and storage formats. Newspaper color printing, for example, can only access a small part of the color space that you can see (the problem is more with the paper than the presses). Even with good color printing, for example, the range of intensities available may be 100:1 or so; the computer screen can usually manage 256:1. So for careful work, an effort should be made to scan from color transparencies, which have a greater dynamic range (1000:1), instead of printed copies.[9] Someone really careful about color representation will find that the typical computer screen doesn't do a really accurate job of color reproduction. There is no substitute for arranging to have a copy of standard color patches (e.g. the Kodak color strip) photographed or scanned along with the original work and carried through into the final display for reference.
With very large images, an important question about compression is what tasks can be done before decompression, or decompression of only part of the image. The most obvious requests are to be able to put forward a low-resolution version of the image while accumulating the bits for the high resolution version, and to be able to crop the image. Wavelet compression permits both operations on the compressed image.
4. Other Processing of Images
Digitally scanned images can be manipulated more easily than traditional photographic images. For example, the overall contrast can be increased or decreased with a few keystrokes; color balances can be changed; and spatial Fourier filtering can be used to separate different components. In fact, this permits considerable improvement of images, and can assist preservation. For example, the edges of printed letters are of high spatial frequency; a waterstain is likely to be of low spatial frequency. Thus, high pass spatial filtering can effectively remove the staining while leaving the letters readable. See George Thoma's work on enhancement techniques for details.[10]
Image processing can also provide the opportunity to do other kinds of image editing and changing. As one example, it is possible to take a videotape of a professional talk and sort the viewgraphs from the pictures of the speaker by looking at the grey scale histogram. The viewgraphs are black and white, with few intermediate values; the speaker's face and clothing will contain a range of tones, with few pixels being either extreme black or extreme white.[11] Having identified the viewgraphs, it is then possible to use them as an index to the videotape. Frame cuts are also easily picked up; if the videotape is reduced to a bitonal representation, if the camera is merely panning or zooming fewer than 10% of the bits will change from one frame to the next, while a cut will produce about 30% new pixel values.
Another, more ambitious task is to classify images automatically into text blocks and graphics blocks. The CORE project, for example, was faced with the need to sort pieces of pages of chemical journals, which are about 25% graphics, into text and illustration. Since the illustrations are mostly line drawings, this can not be done just by looking for intermediate grey-level pixel values as was done with the videotape. Instead, we look through the images for regularly spaced horizontal lines. Looking just at the number of dark bits on each scan line, the text is a regular function, repeating at each line spacing; the illustrations are irregular, with no standard vertical pattern. Thus, we can compute an autocorrelation function on the number of dark bits on each line, and use that to identify text. Figure 4 shows an example:

The process is described in more detail in an earlier paper.[12]
Perhaps the most important new subject is automatic classification of images. Cataloging photograph libraries is an expensive task, and yet people like looking at pictures, so we would like to have a way of putting pictures into categories automatically. For many years this seemed unrealistic, but recent work at IBM has shown some promising results.[13] In the QBIC project, images are classified by basic texture; this seems to produce groupings that are sensible to the viewers and can be used as part of a user interface. As a result, we can now hope for the ability to make large photographic collections available without enormous human effort in cataloging. There is much still to be done (it is not likely that we'll be able to identify people in photographs without traditional records) but at least there is a possibility of providing simpler images in a more useful way.
5. Conclusions
People can read images as rapidly as they can read the same text from Ascii display, or on paper.[15] In our experiments, students looking for information in chemistry articles could go through the articles as quickly in any format. One task, for example. involved reading articles looking for specific facts. The students spent about five minutes reading within each article, whether they had the articles on an image display (from 200 dpi scanning, with an intermediate microfilm step), or in an Ascii display, or as the original paper journal. The software that displayed the images was much easier to write than the software that displayed the Ascii; it had no formatting decisions to make. On the other hand, transmitting the images around the network was much more tedious, and requires higher demands for bandwidth. Nevertheless, the advantages of image scanning have prompted many people to start such projects: for example, Marc Fresko's list of scanning projects includes several hundred.[15] Projects range from the world's agricultural literature 1850-1950 (Cornell), to the Rosenberg atomic espionage case files (Columbia), to the Judaica posters at Harvard, to the archives of the Spanish colonial administration in Seville (IBM). In general, the easiest material to scan is material which was not the highest quality to begin with (i.e. line-art rather than color printing, a book which can be destroyed rather than one which must be preserved, and material which is of interest for its content, not its physical appearance).
Although an image display system can be coded relatively quickly, it is important to design the system for easy use. The scarcest resources are network bandwidth and screen space. In the CORE project, for example, we provided all pages at both 100 dpi and 300 dpi resolution; the 100 dpi pages fit on the screen but are slightly difficult to read, while the 300 dpi images must be panned around, but are clear. See Figure 5 for an example, showing the table of contents of an issue, and parts of a page in both resolutions.
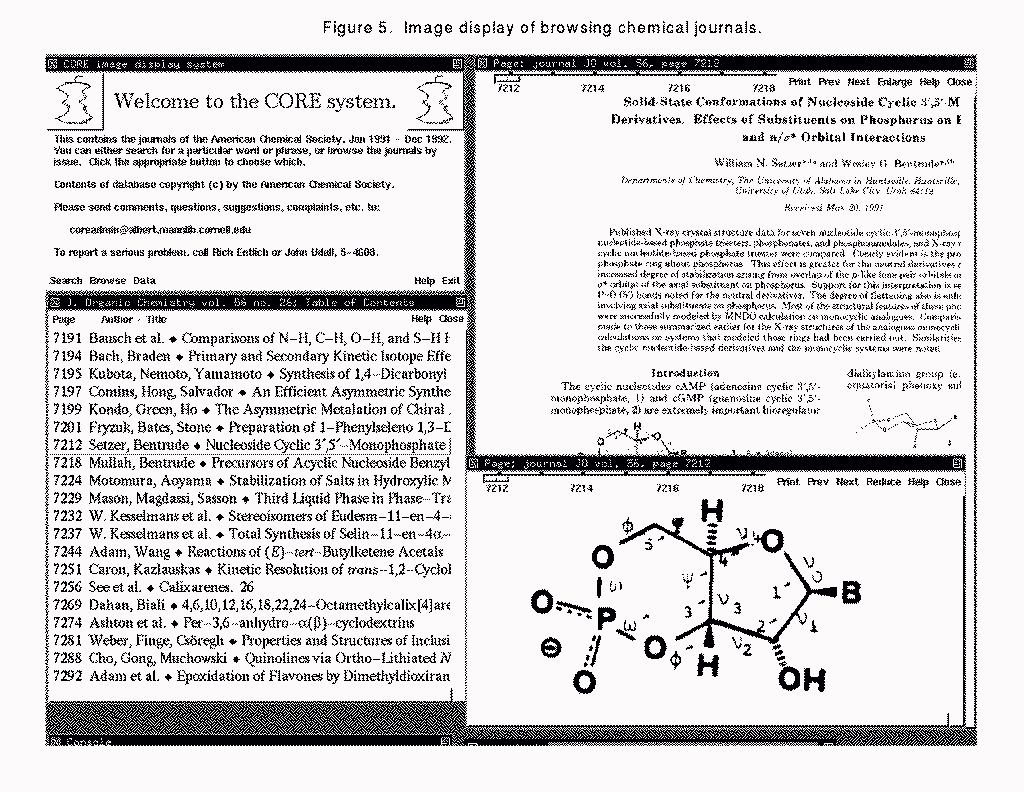
The RightPages project similarly uses 75dpi for initial viewing with the possibility of enlargement.
The most tedious step in making an image library is to provide something that can be used for searching. Most image libraries no longer catalog each individual image, so that the most attractive projects often involve material which is self-describing. For example, the Mellon Foundation is funding the JSTOR project, which is scanning ten important history and economics journals back to their first issue; the idea is to use the scanned images as a replacement for shelf space. In this case, the same finding aids that have been used for the traditional journals can be used for the electronic form, with the additional hope of doing OCR on the images as well.
Most large scale image projects are using CD-ROM as the final distribution medium. This avoids the need to transmit images around a network, and provides permanence and some copy-protection. To gain the greatest advantages from image digitizing, we would prefer networked solutions; this would avoid the need for each library to have copies of the information, permit people to access material without being in libraries, and simplify the interfaces.
To do this, progress is needed in
a)
Reducing digitizing costs. Scanning today, taking the result
of the CLASS project, costs about $30 per book (commercial services,
however, are more likely to charge about $70). Building a
bookstack space for a book on a campus is comparable:
recent stack costs are $20/book at Cornell and $30/book at Berkeley.
A further decrease in the
cost of scanning could be achieved through faster scanners and
sheet feeders; this would make it distinctly cheaper
for libraries to scan books and save shelf space than to put up more
central campus buildings.
b)
Increasing network speeds. If we assume that a user is going to wish
to access a page in 1 second, and the page is coming as a group IV
image of 100 Kbytes, we need about 800 Kbits/sec or
half of a DS-1 circuit (DS-1 is
1.5 Mbits/second). Today, although the Internet backbone is 45 Mbits
going to 155 Mbits/second, most connectivity is at dialup rates (14.4 or
28.8 Kbits/second) or on shared LAN circuits with lower general transmission
rates. In addition, most computers can not decompress a full Group IV image
in one second, nor put the image up on the screen that fast. Faster CPUs
should solve some of these problems, and the network bandwidth is
increasing everywhere. Image libraries present a problem in that they involve a
request for rapid page-turning followed by slow perusal of the page (90
seconds per page on CORE), so that read-ahead caching is likely to be
worthwhile.
c)
Optical character recognition would be very useful for indexing, but is
not critical. There is active development in this industry, and new
projects such as work at Xerox PARC on OCR for old type fonts. At present
OCR is fast enough, but not accurate enough.
d)
Better display screens, with higher resolution, would ease the problems
of interface design. Again, this is happening now and the recent introduction
of active-matrix LCD screens with greater than 640x480 resolution will
encourage the development of better graphics tools for computers.
Finally, we should think ahead to alternate applications, such as video and sound digitization. Sound digitizing is completely practical today, and could for example easily preserve the surviving wax cylinder recordings or be applied to fragile oral history tapes. Video digitizing is being tried in applications such as the CMU digital library project.[16] None of this is easily cataloged or searched mechanically; all relies people's ability to recognize what they want, even if they can not specify it. Experience is that most of the users in a library are ``browsing'' rather than searching, and interviews at Cornell with scholars showed a strong preference for various kinds of browsing rather than Boolean query languages. A demonstration once running at Bell Laboratories showed that even at 10 pages per second, people can spot things of interest to them. And what that means is that the problem of cataloging is perhaps not as serious as it seemed to be, since we can in the end allow people to scan quickly for what they want, rather than arranging searches. Sufficiently fast delivery of images to the user may be a substitute for OCR.
References
1. Barrie T. Stern, "ADONIS-a vision of the future," in Interlending and Document Supply, ed. G. P. Cornish and A. Gallico, pp. 23-33, British Library, 1990.
2. C. McKnight, "Electronic journals-past, present. . .and future?," ASLIB Proc., vol. 45, pp. 7-10, 1993.
3. M. M. Hoffman, L. O'Gorman, G. A. Story, J. Q. Arnold, and N. H. Macdonald, "The RightPages Service: an image-based electronic library," J. Amer. Soc. for Inf. Science, vol. 44, pp. 446-452, 1993.
4. M. Lesk, "Experiments on Access to Digital Libraries: How can Images and Text be Used Together?," Proc. 20th VLDB Conference, pp. 655-667, Santiago, Chile, September, 1994.
5. Anne Kenney and Lynne Personius, Joint Study in Digital Preservation, Commission on Preservation and Access, Washington, DC, 1992. ISBN 1-887334-17-3.
6. Paul Conway and S. Weaver, "The set-up phase of Project Open Book," Microform Review, vol. 23, no. 3, pp. 107-19, 1994.
7. Peter Robinson, The Digitization of Primary Text Sources, Office for Humanities Communication, Oxford University Computing Services, 1993.
8. Michael Ester, "Image quality and viewer perception," Leonardo, pp. 51-63, SIGGRAPH 1990. special issue
9. Efraim Arazi, "Color Portability - Reality in the 90s," SIGGRAPH Panel Proceedings, pp. 15-1 to 15-24, Dallas, Tx, 1990.
10. G. R. Thoma, S. Hauser, F. Walker, and L. Guy, "Electronic imagining techniques in the preservation of the biomedical literature," Electronic Imaging '88, pp. 906-913, Anaheim, CA, 1988.
11. M. E. Lesk, "Television Libraries for Workstations: An All-Digital Storage, Transmission and Display System for Low-Rate Video," in Multimedia Information. Proceedings of the Second International Information Research Conference, eds. Mary Feeney and Shirley Day, pp. 187-194, Churchill College, Cambridge, UK, 15-18 July 1991.
12. M. E. Lesk, "The CORE Electronic Chemistry Library," Proc. 14th ACM SIGIR Conference, pp. 93-112, Chicago, October 13-16, 1991.
13. W. Niblack, R. Barber, W. Equitz, M. Flickner, E. Glasman, D. Petkovic, P. Panker, C. Faloutsos, and G. Taubin, "The QBIC project: querying images by content using color, texture, and shape," Proceedings of the SPIE, vol. 1908, pp. 173-87, Feb. 1993.
14. D. E. Egan, M. E. Lesk, R. D. Ketchum, C. C. Lochbaum, J. R. Remde, M. Littman, and T. K. Landauer, "Hypertext for the Electronic Library? CORE sample results," Proc. Hypertext '91, pp. 299-312, San Antonio, TX, 15-18 Dec. 1991.
15. Marc Fresko, "Sources of Digital Information," BL R&D Report 6102, British Library Research and Development Department, 1994.
16. M. Christel, T. Kanade, M. Mauldin, R. Reddy, M. Sirbu, S. Stevens, and H. Wactlar, "Informedia Digital Video Library," Comm. ACM, vol. 38, no. 4, pp. 57-58, 1995