The Internet has seen explosive growth during the last few years and continues to grow at a staggering rate, adding new users from every imaginable profession each day. The primary reason for the enormous popularity of the Internet is the access it provides to vast and up-to-date repositories of information ranging from television footage to research publications. However, the large number of users and amount of information involved has prompted the need for development of utilities and software tools (termed middleware) that facilitate organization of repositories for easy and efficient access (searching, browsing, and retrieval).
More recently, middleware applications and services such as the World Wide Web, WAIS, gopher, and many others have attempted to organize the masses of information and provide efficient mechanisms for accessing and searching the information space. Although these accomplishments represent a significant advance, the rapid proliferation of new information media, particularly multimedia information such as images, video, and sound, will require new or enhanced middleware services to effectively handle such information.
We are exploring new methods for enhancing middleware services to support effective and efficient access to multimedia information. Specifically, we are developing techniques that allow Internet users to access the information embedded within multimedia documents. The system allows users to manipulate, enhance, and annotate existing information and share these interpretations and modification with other users. Our design extends middleware services to support tools for multimedia data modeling and organization, embedded information extraction (semantic tagging), and efficient network transfer policies such as cooperative proxy server caching, automatic data prefetching, and hierarchical data transfers. The next subsections outline our approaches to multimedia data modeling, embedded information extraction, and efficient network transfer policies.
Multimedia Data Modeling Tools
Multimedia information contains an enormous amount of ''embedded'' information. Moreover, such documents have the potential to convey an infinite amount of ''derived'' or ''associated'' information. To provide access to this embedded information, we are developing tools/services to extract and derive the information hidden in the multimedia data. We are building such services (manipulating the data and interactively defining views and annotations) using the semantic modeling methods we have developed in the MOODS system [GMY93,GYM95]. The system allows users to extract automatically and manually the desired information from an image and/or assign user-dependent information to an image. The extracted and assigned information is then entered back into a database which allows users to efficiently search and query the multimedia information.
Entering the derived or generated data into the database and associating it with the original information gives other users automatic access to the conclusions, thoughts, and annotations of previous users of the information. This ability to modify, adjust, enhance, or add to the global set of information and then share that information with others is a powerful and important service. This type of service requires cooperation between the multimedia data manipulation tools described above and the information repositories scattered across the network. Generated or extracted information must be deposited and linked with existing information so that future users will not only benefit from the original information but also from the careful analysis and insight of previous users.
Embedded Information Extraction Techniques
Conventional semantic information extraction techniques typically involve manual labeling of data.
For example, video footage is frequently annotated by hand for later searches and retrievals. We present a new efficient method for automatic extraction of semantic information from images and video. Our approach works on standard compression schemes such as JPEG, MJPEG and MPEG that are commonly used to capture, store, and transfer (via a network) video and images.
Our embedded information identification method extends the eigenspace approach which was originally proposed in a different context [,]. We show how the eigenspace approach can be modified to work on compressed image and video streams in their compressed format. The result is that we can search images and video very quickly for visual objects like shapes, faces and textures. The objects that are found can be entered back into the database automatically using tools based on MOODS, coupling this powerful search technique with a highly organized and flexible data management framework.
To support an evolving global information base such as the Internet, we must integrate multimedia data manipulation services with existing Internet data repositories and their access methods. In particular, we are integrating the multimedia modeling methods of MOODS and the data extraction techniques we have developed for images and video into the World Wide Web hypertext language (HTML) and the web's data access methods provided by HTTP and ftp.
To support efficient on-line interactive access to digitized information, we are working on enhancements to the existing HTML/HTTP middleware services. These enhancements include strategies for faster network retrieval such as parallel retrieval, cooperative data caching, prefetching and hierarchical data transfers.
The remaining sections discuss in more detail our approach to enhanced middleware. Section 2 elaborates on the object-orient ed framework for modeling multimedia data called MOODS. Section 3 describes one of our new techn iques for efficiently identifying objects in images and video clips. Section 4 describes techniques to impro ve network access to large digital databases. Finally, Section 5 concludes with a summary of our contributions.
The MOODS Multimedia Management System
The goal of our research is to develop a highly flexible information management system capable of providing full access to the embedded information contained in multimedia data. Such a system must support both automatic and manual extraction of embedded information, support for multicomponent multimedia information, user and application specific views of the embedded information, and support for evolving views of the information.
The MOODS system takes an innovative approach to the design of information management systems. Unlike conventional database systems which only support alpha-numeric data or limited access to visual data (e.g., simple storage, retrieval, and display), MOODS provides full access to all the embedded information contained in multimedia data and treats multimedia data like a firstclass object. MOODS combines a database management system with an interactive multimedia data processing system that allows users to access and manipulate the embedded semantic information. The resulting semantic information can then be queried and search using conventional database primitives. Not only does the resulting system support interactive queries and retrievals, but it also provides the functionality required to dynamically extract new or additional embedded information, the functionality to reinterpret existing embedded information, and functionality to define new data/interpretation models.
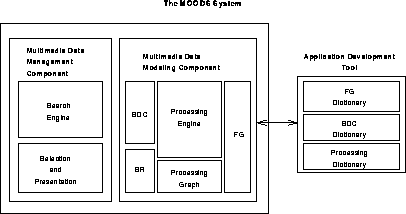
: The components of the MOODS multimedia information
management
system.
Figure 1 illustrates the various components of the MOODS information management system. The system consists of two main components: a database component and a data modeling component. In addition, an application development tool aides in the construction of modeling systems and facilitates reuse of functions an modeling systems.
The data modeling system distinguishes MOODS from conventional information management systems by providing the capability to extract embedded information from stored data. The ability to process data dynamically is important for several reasons. First, the processing engine provides each user and application domain with the ability to dynamically extract the embedded information that is of importance to the user or domain. Second, a dynamic processing engine allows view to be changed or to evolve as new processing techniques become available. Third, dynamic processing reduces the data storage requirements without limiting the amount of information that can be access. Recall that the amount of embedded information is limitless. Static processing schemes severely limit the potential information that can be accessed. This is one of the primary problems plaguing conventional multimedia databases that statically link keys to embedded information. Under MOODS, the system extracts the desired information on demand.
The data modeling system consists of five components. A set of function groups (FG) defines the logical operations that can be applied to the data. The types of semantic information known to the system are represented by a set of semantic data classes (SDC), and a set of semantic relationship (SR) definitions describe the logical relationship between the various semantic data classes. The processing graph defines the transformations that a data item may legally undergo over its lifetime. Finally a runtime processing engine allows users of the system to interactively apply functions to extract and identify embedded information subject to the constraints imposed by the five components described above.
The database component is tightly integrated with the modeling system. After the modeling system has extracted the embedded information, the extracted semantic information is automatically entered into and becomes available to the database for search or browsing via conventional database techniques. The transfer of information from the modeling system to the database means that any new information identified (or reinterpreted) by the modeling system will be made available to the user(s). Using the SR definitions, the database also supports queries on data that has not been processed or has not been processed to the level required by the query. For example, a query for a ``Cheverolet Camaro'' may be satisfied by locating all data items that contain a car and analyzing them further to determine the car's model. In this case, the database dynamically invokes the services of the modeling system.
The application development system is an auxiliary tool that aids in the development of new modeling systems. In particular, it maintains a complete database of all known (previously defined) function groups, semantic classes, semantic relationship models, and processing graphs. The tool allows users to construct new data models by defining their own semantic classes, relationships, and graphs, or by incorporating and combining existing structures. Data model reuse is fostered by allowing newly developed data models to be added to the tool's database for use in future models. The system also allows users to quickly modify or convert an existing model to meet their personal needs or the needs of their application domain.
To utilize the information present in multimedia data, the data must first
be processed (automatically or manually) to obtain its meaningful
components and the information it conveys.
We refer to these basic components as structural objects.
Example structural objects in an image might be
regions of uniform intensity,
an edge boundary, curved segments, or regions of uniform texture.
An audio stream might contain regions consisting of a single pitch or
frequency or regions containing bursts of sound.
These structural objects contain no semantic information other than
basic structural features.
However, given an application domain (e.g., medical imaging,
cartography, or meteorology), additional semantic information can be
associated with a structural object or set of structural objects.
Each structural object corresponds to some object or semantic category
in the current application domain.
We call the domain-dependent categories domain objects. Each
application domain typically has a reasonably well-defined set of
domain objects (e.g., ventrical or tumor in medical imaging) that
provide useful domain-dependent information about the structural
object.
It is precisely this
structural object  domain
object
mapping that must be established during the embedded information
extraction process.
domain
object
mapping that must be established during the embedded information
extraction process.
To illustrate the MOODS runtime operation, consider a meteorology system. Initially an (expert) meteorologist would use the application development tool to construct a multimedia data model that can extract weather information from satellite photos, heat maps, etc. This involves defining the image processing transformations and image processing functions that can be applied to extract and assign semantic meaning to the embedded information in the images.
Having defined the set of legal transformations a satellite photograph may undergo to extract the semantic meaning, the meteorologist must then define data-specific transformations that will later be used to enter data into the database. For example, the meteorologist may define one transformation process for satellite images taken at close range of smaller regions (e.g., the state of Kentucky) and another transformation process for satellite images of larger regions (e.g., the continental United States). Once defined, new images will be automatically processed according to the appropriate transformation model and the resulting semantic information will be entered into the database.
A different meteorologist may then search the database for images containing storm activity. Using the extracted semantic information, the system will return a list of images containing stormy activity. The meteorologist may then decide to invoke the processing engine on one of the returned images to further identify the intensity of a particular storm in the image. This information will then be entered back into the database and will respond to searches asking for storms with a particular intensity.
The MOODS data modeling component supports an object-oriented model for manipulating multimedia data. To extract the embedded information from a multimedia object, a user manually or automatically pushes the multimedia object through a series of transformations to identify the important semantic information in the object. At any given point in the transformation process, the object has a semantic meaning which is made known to the database so that the object and can be selected via conventional database search/query strategies. To support semantic objects that can be manually or automatically manipulated by the user, the MOODS system provides an enhanced object-oriented programming/object-manipulation environment with the following salient features:
- Dynamic Data Semantics:
- The semantics associated with the data in an object will typically change often over the object's lifetime. Therefore, it is important to dynamically change the set of functions (operations) associated with an object after it is instantiated. That is, the set of functions associated with an object depends on the object's current semantic meaning. As the object is processed its semantic meaning changes resulting in a new set of functions that can be applied. For example, a satellite photograph of urban city may initially have only have the semantic meaning ``an image'' and applicable functions ``enhance'', ``segmentation'' and ``edge-detect''. However, after executing an edge-detection function, the semantic meaning may have changed to ``an image of edges'' and now has available new functions to identify edges that represent roads and functions that identify other edges a buildings. As the semantics of the image evolve, the set of functions available to the object become more specific and powerful. Also, functions that no longer make sense may be removed. For example, segmentation on an ``edge-image'' makes no sense and would be removed.
- Abstract Function Types:
- Given an image, one usually has a wide range of functions available that can perform a particular image processing operation. An example of such an operation is edge detection. Several edge detection techniques exist and new methods continue to emerge. Each technique implements a different/new algorithm and may be appropriate under different circumstances. Thus, given an image object, it is advantageous not to bind the data to a particular function, but rather to an abstract function class and dynamically select an appropriate function from the abstract class at runtime.
Abstract functions simply define a logical operation, not the implementation, and postpones the binding of the actual implementation until runtime. In many cases, binding can be done automatically at runtime based on the current semantics of the data. As a result, the abstract function completely hides the implementation of the function from the user much like an abstract data type hides its implementation.
- Inheritance:
- Given a raw image, two or more users (or applications) might process the same image and obtain different semantic data to be used for different purposes. For example, a satellite image might be of interest to both a geologist and a military analyst. Initial processing of the raw image (such as noise removal, enhancements) might be common to both applications before domain-specific processing takes over. In such situations, it is important to group common operations and objects together in a class and then let individual applications inherit the image attributes in a subclass avoiding duplication of efforts.
- Composition:
- Composition refers to the merging of two or more distinct objects into a new object. For example, two independent pictures of the same scene may be merged together to produce additional information about the scene (e.g., the depth of objects in the scene). Alternatively, a single facial image might be processed to extract the individual facial features, modify some of the features, and then merge the modified facial features back together to create an object that can be easily searched for certain combinations of facial feature characteristics. In other words, the system must provide the ability to combine processed objects together into compound objects with new functionality that did not exist when the objects were independent.
- History mechanism:
- As discussed earlier, an image typically goes through a series of transformations that extract information from the image or compute new information based on the image. Thus, the state of an object must contain not only the current data and associated semantics, but also the sequence of operations that were applied to the original object to bring it to the current state. Such a history is especially useful in an interactive programming system where a user may wish to test a variety of alternatives for processing the visual information.
Note that a history mechanism also includes the notion of saving the results of past processing so that it can be reused by future users/applications. Alternatively, the original user may wish to backtrack to a previous version of the data and resume processing from that point onward.
- The semantics associated with the data in an object will typically change often over the object's lifetime. Therefore, it is important to dynamically change the set of functions (operations) associated with an object after it is instantiated. That is, the set of functions associated with an object depends on the object's current semantic meaning. As the object is processed its semantic meaning changes resulting in a new set of functions that can be applied. For example, a satellite photograph of urban city may initially have only have the semantic meaning ``an image'' and applicable functions ``enhance'', ``segmentation'' and ``edge-detect''. However, after executing an edge-detection function, the semantic meaning may have changed to ``an image of edges'' and now has available new functions to identify edges that represent roads and functions that identify other edges a buildings. As the semantics of the image evolve, the set of functions available to the object become more specific and powerful. Also, functions that no longer make sense may be removed. For example, segmentation on an ``edge-image'' makes no sense and would be removed.
We have implemented a prototype system that allows users to define abstract function groups, semantic data classes, and a semantic processing graphs that can be used to interactively processes images to extract the embedded semantic information. The semantic information, along with the associated images, are then entered into a database (Illustra) for later retrieval. To demonstrate the power of the system, We have use the prototype to construct a processing tool that does simple feature recognition, music recognition, document title/author identification, and paleographic letter form identification in the Beowulf manuscript.
Identifying the content of digital data forms can be done most reliably by hand, but the large volume of data that is now available makes autonomous techniques necessary. Researchers in image processing and computer vision have long addressed problems such as pattern classification, object recognition and motion detection. Very few techniques, however, have been applied to the problem of extracting and storing information from video clips.
Our new approach for tagging semantic information in video clips is based on the Karhunen-Loeve (KL) transform [Fuk90], which has been used by others for face recognition [TP91] and object recognition [MN95]. The key idea to the efficiency of our approach is that we exploit the fact that video clips are stored digitally in a transformed, compressed format. The potential loss of fidelity is completely controllable, ranging from almost no loss to a large amount of distortion. This transformed format is the basis for the video storage standards that are now in place, including the full motion JPEG (MJPEG) and MPEG formats.
The standard MJPEG and MPEG formats are actually algorithms that transform a video through many steps with the goal of reducing the storage size. Classical approaches to the video semantic search problem completely decode (uncompress) each frame of the video and then search the pixels of the frame for objects to classify or recognize. Our approach can classify objects in the compressed stream without fully restoring (uncompressing) the video to the individual pixel level. Avoiding the complete restoration to the pixel level improves the system's computational efficiency without a loss in classification ability.
The basic idea behind the eigenspace method is to represent a large number of ``training'' images with a lower-dimensional subspace. When a new image is seen, it can be classified as being similar or very different from the training images with just a few operations in the pre-computed subspace. For example, one could compile a large number of images of an object like the White House. Once these training images are distilled using the Karhunen-Loeve (KL) transform, any new image can be classified as ``containing the White House'' or ``not containing the White House''.
Specifically, let the input to the KL process be a set of images
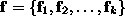 , represented
as vectors, where each image in
, represented
as vectors, where each image in 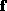 has
has
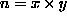 pixels.
We treat an image as a vector by placing the pixel values in
scanline order.
The first step in computing the KL transform is to subtract from each
input vector the average value
pixels.
We treat an image as a vector by placing the pixel values in
scanline order.
The first step in computing the KL transform is to subtract from each
input vector the average value

of the input vector set.
This generates a new vector set
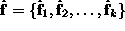 where
where 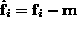 for
for 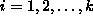 .
.
Now we compute the covariance matrix 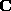 of the mean-adjusted input
vectors
of the mean-adjusted input
vectors 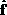 :
:
The KL transform is obtained from the eigenvectors and eigenvalues
of 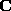 by solving an eigenstructure
decomposition of the form:
by solving an eigenstructure
decomposition of the form:

This decomposition produces n eigenvectors
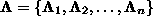 and
their associated eigenvalues
and
their associated eigenvalues
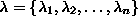 .
Because
.
Because 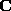 is real and symmetric, the
eigenvectors are complete
and orthogonal, forming a basis that spans the n-dimensional space.
Thus, using the eigenvectors as a basis, the original input vectors
is real and symmetric, the
eigenvectors are complete
and orthogonal, forming a basis that spans the n-dimensional space.
Thus, using the eigenvectors as a basis, the original input vectors
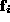 can be described exactly as
can be described exactly as
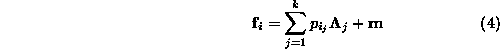
where, as before,  is the mean of the
input vector set.
is the mean of the
input vector set.
All k eigenvectors are needed in order for the equality to hold.
But one attractive property of the eigenspace representation is that
the eigenvectors can be ordered according to their associated
eigenvalues.
The first (largest) eigenvector is the most significant, encoding the
largest variation of the input vector set.
This ordering allows the original input vectors to be approximated by
the first w eigenvectors
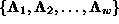 with
with  :
:
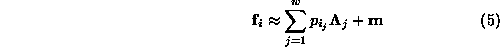
Given two vectors that are projected into eigenspace, it is a well-known fact that the closer the projections in eigenspace, the more highly correlated the original vectors [MN95]. This gives us the following important fact:
Distance in eigenspace is an approximation of cross-correlation in the image domain.The result is that the eigenspace gives a very powerful way to classify an image with respect to a set of known images. One can simply project the new image to eigenspace and measure its Euclidean distance to the other known points in eigenspace. The closest neighbors are projected images which correlate the highest with the input.
The main idea of our work is to formulate the eigenspace approach on input vectors that are not image pixel values, but have been transformed from the image domain to another representation. The semi-compressed domain is convenient since it is an intermediate form that compressed video frames and images must pass through during decompression.
The critical fact we have proven[] is that
Distance in the eigenspace constructed from semi-compressed vectors is an approximation of cross-correlation in the image domain.One implication of this fact is that videos can be searched automatically for content using the eigenspace approach without first decoding them. This gives a big gain in efficiency without much loss of classification performance.

: The input video sequence appears on the left while
the faces identified appear on the right.
The white boxed frames are those recognized as containing subject 27.
Black boxed frames are false matches.
We demonstrate the results of our method using a short (56 frame) video clip of a human face. The goal is to identify people (faces) that appear in an MPEG video clip without completely decoding the MPEG.
We constructed a semi-compressed-domain eigenspace from two poses of
26 people in the Olivetti
Face Database
 and two poses from
a local subject. The local subject,
the 27th person, was also the subject pictured in the
test video clip.
Figure 2 shows the 56 frame video clip on
the left.
The four pictures on the right show the poses from the database that
were found to be present somewhere in the video.
The top two images on the right are the two
poses of subject 27 who was correctly identified.
The two poses of subject 27 were taken on different days, with different
clothes and under different lighting conditions than the video clip.
and two poses from
a local subject. The local subject,
the 27th person, was also the subject pictured in the
test video clip.
Figure 2 shows the 56 frame video clip on
the left.
The four pictures on the right show the poses from the database that
were found to be present somewhere in the video.
The top two images on the right are the two
poses of subject 27 who was correctly identified.
The two poses of subject 27 were taken on different days, with different
clothes and under different lighting conditions than the video clip.
Matching was done in the semi-compressed eigenspace, using only the DCT frames of the MPEG sequence. We used 10 eigenvectors (of the possible 54) for the results shown. This was because of scale, since the scale of subject 18 matches those frames better than subject 27. The highlighted boxes in the video sequence on the left identify the frames that were found to match an image from the database. Frames 40 - 47 were correctly recognized as subject 27. Only frames 51 and 52 were incorrectly identified as matching subject 18 from the database. Despite the efficiency and accuracy of our algorithm, this example shows that false positives are still possible and a higher-level thresholding policy must be used to eliminate these false matches.
Finally, we measured the computational time necessary for scanning the frames of an MPEG video clip. We instrumented the public domain MPEG software from UC-Berkeley, and compared the execution time for obtaining DCT frames (before the inverse DCT) to the time necessary to obtain the complete image (after the inverse DCT). We found that the dominant cost is the inverse DCT, and that obtaining only the DCT frames takes one half the time of completely decoding the images.
Network Access To Multimedia Data
Although existing Internet middleware tools such as the WorldWideWeb, Gopher, Archie, and others provide access to multimedia information, we believe that they are not capable of dealing with the massive scale and size of typical digitized documents and their associated information i.e., annotations. For instance, a Beowulf manuscript consists of hundreds of pages of high fidelity images where each image is 21 MB or larger [Kie95,Kie94a,Kie94b]. Existing tools are not designed to allow user manipulation of the information on this scale and to efficiently handle (display/search/browse) the massive digitized documents we envision.
To support efficient on-line interactive access to such digitized information, we are investigating the following enhancements to the existing HTML/HTTP middleware services:
Cooperative Data Caching and Parallel Retrieval
Currently, HTTP proxy servers support a limited form of information caching[LA94] in which a p roxy server caches information accessed on behalf of several nearby clients, typically located on a LAN. However, proxy servers located within the same geographical region do not communicate with each other to share information in their caches. Instead, a proxy server contacts the original information provider (e.g. server at a given URL) whenever the desired information is not found in its cache. This organizational structure can still cause bottlenecks at popular URL servers and does not use network bandwidth efficiently. An alternative is to dynamically discover proxy servers in the immediate vicinity that currently cache the desired information. For scalability reasons, such cooperation among proxy servers should be as stateless as possible for scalability.
We have extended the HTTP proxy server mechanism to exploit the IP/UDP Multicast (group communication) to dynamically locate other proxy servers that have the desired URL document in their caches. To reduce the host processing bottlenecks at proxy servers and allow real-time retrieval and playback of multimedia documents, we have added extensions for parallel retrieval of parts of a document from different proxy servers.
To hide the communication latencies across a WAN that spans a huge geographic area as the Internet requires heuristic algorithms that predict future access patterns with a high degree of confidence and moves documents to local or proxie caches in advance of the need for the data. We are examining automated methods for predicting future document accesses based on past access histories [GA94] . Such methods must be careful not to waste valuable (shared) Internet bandwidth on unnecessary data but yet make the maximal amount of data locally available before the data is accessed.
We have developed a heuristic-based prefetching algorithm that can, with high accuracy, retrieve multimedia documents before they are needed. The algorithm takes a probabilistic approach using a probability graph that limits the amount of information that needs to be maintained about past accesses but yet can select prefetch documents with a high degree of confidence.
Responsiveness of an on-line data access system depends largely on the quality of the underlying communication link. With the proliferation of various network technologies including wireless communication and slow-speed dial-up links, an on-line data access/retrieval system must be designed to perform well over slow speed links as well as congested network paths. One increasingly popular technique for accommodating heterogeneous networks is hierarchical encoding. Multimedia information is stored at multiple resolutions, and the appropriate level of resolution is selected and transferred automatically based on parameters such as the speed of the link. We are currently investigating techniques for the use of hierarchical data encoding in digital libraries. For example, if a user wishes to view an archived manuscript on-line when the network is congested, the system automatically compensates for the low transfer rate by fetching a lower-resolution version of the image data. Users who wish to wait can still run the system in a fixed-resolution mode. However, quick access to lower resolution contents is often desirable when browsing a document. Dynamic hierarchical data transfer requires new encoding and storage formats and also adaptable communication protocols. This is the focus of some of our ongoing research.
Digitized multimedia data such as images, video, and audio is rapidly becomming commonplace will soon replace conventional alpha-numeric data as the primary data format. New techniques are need to access, manage, and search these new multimedia data types. We have presented a flexible multimedia data management system called MOODS that treats the embedded semantic information contained in a multimedia document as a first class entity that can be identified and searched for like conventional data. We also presented an efficient algorithm for automatic identification of semantic information in a compressed images and video. Finally, we described extensions to existing middleware languages and protocols such as HTML/HTTP to improve remote network access to multimedia data, an increasingly important problem as we move to a completely networked world.
- Fuk90
-
K. Fukunaga.
Introduction to Statistical Recognition.
Academic Press, 1990.
- GA94
-
James Griffioen and Randy Appleton.
Reducing File System Latency using a Predictive Approach.
In Proceedings of the 1994 Summer USENIX Conference, June 1994.
- GMY93
-
James Griffioen, Rajiv Mehrotra, and Rajendra Yavatkar.
An Object-Oriented Model for Image Information
Representation.
In Proceedings of the Second International Conference on
Information and Knowledge Management, Nov 1993.
- GYM95
-
J. Griffioen, R. Yavatkar, and R. Mehrotra.
A Semantic Data Model for Embedded Image Information.
In Proceedings of the 1994 IST/SPIE Symposium on Electronic
Imaging Science and Technology, February 1995.
- Kie94a
-
Kevin Kiernan.
Electronic Beowulf.
National Geographic, December 1994.
- Kie94b
-
Kevin Kiernan.
Scholarly Publishing on the Electronic Networks: Gateways,
Gatekeepers, and Roles in the Information Omniverse.
Digital Preservation, Restoration, and Dissemination of Medieval
Manuscripts, 1994.
- Kie95
-
Kevin Kiernan.
The Electronic Beowulf.
Computers in Libraries, February 1995.
- LA94
-
Ari Luotenen and Kevin Altis.
World Wide Web Proxies.
In Proceedings of the CERN WWW Conference, August 1994.
- MN95
-
H. Murase and S. Nayar.
Visual learning and recognition of 3-D objects from appearance.
International Journal of Computer Vision, 14:5--24, 1995.
- TP91
- M. Turk and A. Pentland. Eigenfaces for recognition. Journal of Cognitive Neuroscience, 3(1), 1991.
Griffioen/Seales
James Griffioen
Mon Oct 9 17:54:30 EDT 1995